Variable not found
Enlaces interesantes 642
marzo 23, 2026 07:02

La semana pasada encontré gran cantidad de contenidos interesantes sobre desarrollo web, .NET, IA, acceso a datos, MAUI y otros temas, aunque me gustaría destacar varios artículos, todos relacionados con la inteligencia artificial, a los que, como mínimo, deberías echarles un vistazo.
En primer lugar, Fernando Escolar nos explica detalladamente las distintas piezas que componen un agente de IA, y cómo se relacionan entre sí.
Miguel Durán comparte un proyecto personal que ha creado para comprobar qué modelos de IA podemos ejecutar en nuestra máquina local, muy útil para usar IA generativa sin pasar por caja y sin enviar datos hacia fuera.
Por último, Addy Osmani nos habla de la deuda de comprensión que se genera al usar código generado por IA, y cómo esto puede afectar a los desarrolladores a largo plazo.
El resto de enlaces, a continuación.
Por si te lo perdiste...
- Aprovecha al máximo los archivos .http en Visual Studio usando variables dinámicas
José M. Aguilar - Backing fields en Entity Framework Core
José M. Aguilar
.NET
- C# class types explained with examples
David Grace - CoreSync: a .NET library that provides data synchronization between databases
Adolfo Marinucci - records ToString and inheritence
Steven Giesel - Implementing RFC-compliant HTTP caching for HttpClient in .NET
Gérald Barré - C# 14 New Features: A Developer Guide for .NET 10
Dirk Strauss - Writing a .NET Garbage Collector in C# - Part 9: Frozen segments and new allocation strategy
Kevin Gosse - Local LLM Chat Completions in .NET — Just C#
Bruno Capuano - Implementing the Strategy Pattern with .NET Dependency Injection
Ricardo Peres
ASP.NET Core / ASP.NET / Blazor
- Code Blocks in Blazor Rich Text Editor: Setup and Best Practices
Saravanan G. - Blazor Basics: Implementing a Theme Switch in Blazor (Dark Mode)
Claudio Bernasconi - Green Dashboard, Dead Application
Martin Stühmer
Azure / Cloud
- Your Azure SQL Backups Won't Save You (Here's Why)
Martin Stühmer - Lost Your SSH Key to an Azure VM? Don’t Panic. Here’s the Fix.
Shannon B. Kuehn - How to Evaluate, Test, and Demo Azure Local
Thomas Maurer
Conceptos / Patrones / Buenas prácticas
- Scrum en la era de la IA: la síntesis que viene
Juan Palacio Bañeres - Decorator Design Pattern in C#: Complete Guide with Examples
Nick Cosentino - The unwritten laws of software engineering
Anton Zaides - Look Bro, I Know How to Write Good Code
Rob Conery
Data
- How to Seed Data to EF Core
Ricardo Peres - Dapper in Depth with ASP.NET Core 10
Soumyadip Majumder - Optimizing Bulk Database Updates in .NET: From Naive to Lightning-Fast
Milan Jovanović - When NOT to use the repository pattern in EF Core
Ali Hamza Ansari - Entity Framework Extensions Options Explained: Everything You Can Customize
Anton Martyniuk - Deploy SQL Scripts Effectively in Production
Jared Westover - Microsoft.Data.SqlClient 7.0 Is Here: A Leaner, More Modular Driver for SQL Server
David Levy
Machine learning / IA
- Subvencioname un pico de IA
Braulio Díez - Anatomía de un agente de IA
Fernando Escolar - CanIRun.ai — Can your machine run AI models?
Miguel Durán - Introducing OpenAI’s GPT-5.4 mini and GPT-5.4 nano for low-latency AI
OpenAI - What's New in Agent Skills: Code Skills, Script Execution, and Approval for Python
Sergey Menshykh - Random Forest Regression Using C#
James McCaffrey - AI Benefits - But at What Cost?
Steve Smith - How Large Language Models Are Built and Work — Complete Technical Guide
CostlyInfra - Comprehension Debt — the hidden cost of AI generated code
Addy Osmani
Web / HTML / CSS / Javascript / Frontend
- Angular 16 y programación funcional para código limpio
David Filipe Lopes Domingues - Native Random Values in CSS
Alvaro Montoro - 4 Reasons That Make Tailwind Great for Building Layouts
Zell Liew - Building dynamic toggletips using anchored container queries
Daniel Schwartz - Flexbox Masonry Layout (Explained with Math)
Ibrahim Bendebka - BaseWatch — Track CSS & Browser Feature Support, Get Baseline Alerts
Filippo Tinnirello - JavaScript for Everyone: Destructuring
Mat Marquis - Image Gallery with Popovers and AIM (Anchor-Interpolated Morph)
Chris Coyier - Modal vs. Separate Page: UX Decision Tree
Vitaly Friedman - Introducing Angular Testing Library Zoneless
Tim Deschryver - Text scaling support in Chrome Canary
Chris Coyier - Dropdowns Inside Scrollable Containers: Why They Break And How To Fix Them Properly
Godstime Aburu
Visual Studio / Complementos / Herramientas
- Awesome GitHub Copilot just got a website, and a learning hub, and plugins!
Matt Soucoup - How VS Code Builds with AI
Pierce Boggan
.NET MAUI
- MAUI Avalonia Preview 1
Tim Miller - Pin Clustering in .NET MAUI Maps
David Ortinau - How to Implement Accessibility in .NET MAUI
Leomaris Reyes - When Visual Studio Forgets Your Phone: Building an Automated Solution
Chris Miller - Logging in .NET MAUI Apps
Tomasz Cielecki - Accelerating .NET MAUI Development with AI Agents
Agus Riyadi - How to Extract Data from PDFs in .NET MAUI iOS Apps Using C#
Sumathi Uthayakumar - Build Once, Run Everywhere: Blazor Hybrid PDF Viewer for WinForms, WPF, and .NET MAUI
Parthipan R.
Otros
Publicado en Variable not found.
Variable not found
¡Ojo a los parámetros IEnumerable<T>!
marzo 17, 2026 07:02

En .NET, es bastante habitual que nuestros métodos o funciones reciban objetos de tipo IEnumerable<T> con la intención de que iteremos sobre ellos para lograr el comportamiento deseado. Esta abstracción es muy poderosa, ya que nos permite trabajar con cualquier colección o secuencia de datos sin preocuparnos por su implementación concreta, pero, si no somos cuidadosos, puede llevarnos a errores y comportamientos inesperados.
Por ejemplo, es muy frecuente realizar múltiples enumeraciones sobre la misma instancia de IEnumerable<T>, algo que a veces puede ocurrir de forma inconsciente, y se convierte en un problema cuando la secuencia es muy extensa o su contenido no es replicable. De hecho, muchas herramientas y entornos de desarrollo nos advierten sobre este problema durante la edición y compilación para que estemos atentos.
Otro problema común es asumir que la secuencia es finita, algo que no tiene por qué ser siempre cierto. Las enumeraciones en este caso pueden llevar a bucles infinitos o a un consumo excesivo de recursos.
En este artículo exploraremos distintos escenarios que pueden darse y cómo podemos evitarlos.
¿Qué es una enumeración múltiple?
Una enumeración múltiple ocurre cuando un método o función recorre una secuencia de datos más de una vez. Esto puede suceder de forma explícita, por ejemplo, si tenemos dos bucles foreach que iteran sobre la misma secuencia, o de forma implícita, como cuando llamamos a varios métodos como Count(), ToList(), Last(), etc. sobre la misma colección.
Cuando se trata de una colección en memoria, como una lista o un array, no suele haber problema al realizar enumeraciones múltiples, ya que estas estructuras permiten recorrerlas tantas veces como sea necesario sin incurrir en un coste significativo.
Sin embargo, si la secuencia es generada dinámicamente, como una consulta LINQ a una base de datos o aquellas producidas por un iterador, cada operación de enumeración puede implicar un coste considerable, tanto en términos de rendimiento como de recursos, lo que hace que la enumeración múltiple pueda ser problemática.
Pero además, el contenido de la secuencia puede variar entre distintas enumeraciones, lo que puede llevar a resultados inconsistentes o errores inesperados. Es lo que llamamos "secuencias no replicables".
¿Qué es una secuencia no replicable?
Una secuencia no replicable es aquella que no puede ser recorrida múltiples veces de manera segura. Un ejemplo típico es una consulta LINQ que se ejecuta contra una base de datos, datos procedentes de un stream o una secuencia generada por un iterador que produce valores bajo demanda. En ninguno de esos casos podemos garantizar que la secuencia se mantenga igual entre diferentes enumeraciones, o incluso que esté disponible para una segunda enumeración (por ejemplo, los datos podrían haber cambiado en la base de datos).
Por ejemplo, observad una función como la siguiente, que recibe un objeto IEnumerable<int>, muestra el número de elementos recibidos e itera dos veces sobre ellos para procesarlos:
static void Process(IEnumerable<int> numbers)
{
Console.WriteLine($"Processing {numbers.Count()} numbers");
Console.WriteLine("First pass");
foreach (var number in numbers)
{
Console.WriteLine($" Doing something with {number}");
DoSomething(number);
}
Console.WriteLine("Second pass");
foreach (var number in numbers)
{
Console.WriteLine($" Doing another thing with {number}");
DoAnotherThing(number);
}
}
Si el objeto enviado a la función Process() se encontraba ya en memoria, por ejemplo en forma de una lista (List<int>) o array (int[]), el código anterior funcionará sin problemas. La ejecución será consistente y predecible, los elementos se contarán de forma correcta y ambos bucles foreach los recorrerán, por lo que la salida en consola será idéntica en las dos vueltas.
Process([1, 2, 3]);
Processing 3 numbers
First pass
Doing something with 1
Doing something with 2
Doing something with 3
Second pass
Doing another thing with 1
Doing another thing with 2
Doing another thing with 3
Sin embargo, imaginad que lo que enviamos es una consulta LINQ que se ejecuta contra una base de datos. En ese caso, la llamada a Count() ejecutará la consulta para obtener el número de elementos. Tras ello, el primer foreach ejecutará de nuevo la consulta y obtendrá los resultados, y el segundo foreach volverá a ejecutarla. Esto, además de suponer potencialmente un problema de rendimiento, puede devolver en cada caso un conjunto diferente de resultados o incluso lanzar una excepción si la conexión a la base de datos ya no está disponible.
Lo mismo puede ocurrir si la secuencia es generada por un iterador que produce valores bajo demanda, como en el siguiente ejemplo. Como podéis ver, se trata de una función generadora que devuelve entre 3 y 7 números aleatorios en el rango 1-9 cada vez que se itera sobre ella:
static IEnumerable<int> GenerateNumbers()
{
for (int i = 0; i < Random.Shared.Next(3, 8); i++)
{
yield return Random.Shared.Next(1, 10);
}
}
En este caso, cada llamada a GenerateNumbers() produce una secuencia diferente de números. Por lo tanto, si pasamos esta función generadora a nuestro método Process(), veremos que cada vez que enumeramos la secuencia obtenemos resultados distintos, tanto en el número de elementos como en los propios valores:
Process(GenerateNumbers());
Processing 2 numbers
First pass
Doing something with 9
Doing something with 8
Doing something with 2
Doing something with 3
Doing something with 4
Doing something with 9
Doing something with 8
Second pass
Doing another thing with 5
Doing another thing with 3
Doing another thing with 2
Observad que, en este caso, cada enumeración de la secuencia ha producido un conjunto diferente de números, lo que puede llevar a comportamientos inesperados en nuestro código, como el que vemos en la salida anterior.
Por tanto, cuando escribimos un método o función que acepta parámetros de tipo IEnumerable<T>, debemos ser conscientes de que estamos abriendo la puerta a que un consumidor realice invocaciones enviando secuencias no replicables.
¿Qué son las secuencias infinitas?
Otra situación problemática es cuando la secuencia recibida es infinita. Esto puede ocurrir, por ejemplo, si la secuencia es generada por un iterador que produce valores de forma indefinida, como la siguiente:
static IEnumerable<int> InfiniteNumbers()
{
int i = 0;
while (true)
{
yield return (i++) % 10;
}
}
Esta secuencia generará números indefinidamente, repitiendo los dígitos del 0 al 9, por lo que cualquier intento de recorrerla por completo derivará en un bucle infinito. De hecho, si pasamos esta secuencia a nuestro método Process(), la llamada a Count() intentará contar todos los elementos y dará lugar a un bloqueo de la aplicación.
¿Qué podemos hacer para evitar estos problemas?
Afortunadamente, hay soluciones sencillas para evitar los comportamientos inesperados cuando trabajamos con parámetros de tipo IEnumerable<T>.
La opción más recomendable sería intentar refactorizar el método para que no sea necesario realizar más de una enumeración de la secuencia recibida. En el caso anterior es complicado porque el Count() inicial ya implica una enumeración, pero quizás funcionalmente podría ser prescindible o sustituible por otro enfoque similar:
static void Process(IEnumerable<int> numbers)
{
var count = 0;
foreach (var number in numbers)
{
count++;
Console.WriteLine($" Doing something with {number}");
DoSomething(number);
Console.WriteLine($" Doing another thing with {number}");
DoAnotherThing(number);
}
Console.WriteLine($"{count} numbers processed");
}
Sin duda esta es la mejor opción porque evita todos los problemas de raíz, sin sacrificar rendimiento ni la flexibilidad de recibir un objeto de tipo IEnumerable<T>. Además, permitiría detener la enumeración en cualquier momento, cuando ya no sea necesario procesar más elementos, sin necesidad de recorrer la secuencia completa.
Sin embargo, no siempre será posible.
Otra opción es bajar el nivel de abstracción y cambiar el tipo de datos del parámetro, para asegurar que solo se puedan enviar colecciones que ya estén materializadas en memoria y que, por tanto, sean replicables. Por ejemplo, podríamos cambiar la firma del método para recibir objetos IReadOnlyCollection<T> o IReadOnlyList<T>, lo que garantiza que la colección es fija y puede ser recorrida múltiples veces sin problemas.
La diferencia principal entre
IReadOnlyCollection<T>eIReadOnlyList<T>es que la primera solo garantiza que la colección tiene un tamaño definido y puede ser contada, mientras que la segunda también permite acceder a los elementos por índice. En este caso, cualquiera de las dos opciones sería válida.
static void Process(IReadOnlyCollection<int> numbers)
{
... // El resto del código permanece igual
}
A veces, esto requerirá que los consumidores del método tengan que adaptar su código para enviar colecciones materializadas, pero a cambio evitamos cualquier riesgo de múltiples enumeraciones inesperadas. También estaremos protegiéndonos contra secuencias infinitas, ya que ningún consumidor podrá enviar una secuencia que no tenga un tamaño definido.
// Código del consumidor
var items = GenerateNumbers().ToList(); // Materializamos la secuencia
Process(items);
Si ninguna de las opciones anteriores es viable, siempre podemos optar por materializar la secuencia recibida al inicio del método, almacenándola en una lista o array. De esta forma, nos aseguramos de que cualquier enumeración posterior se realice sobre una colección fija y replicable.
static void Process(IEnumerable<int> numbers)
{
var materializedNumbers = numbers.ToList(); // Materializamos la secuencia
... // El resto del código permanece igual, pero usando materializedNumbers
}
El inconveniente de esto es que, si la secuencia original es muy grande, podríamos estar consumiendo una cantidad significativa de memoria. Tampoco tendremos protección contra secuencias infinitas, ya que la llamada a ToList() intentará recorrer toda la secuencia para materializarla.
Conclusión
En resumen, cuando trabajamos con parámetros de tipo IEnumerable<T>, debemos ser conscientes de los posibles problemas que pueden surgir debido a múltiples enumeraciones o secuencias infinitas. Adoptar buenas prácticas y elegir la estrategia adecuada según el contexto nos ayudará a evitar errores y a escribir código más robusto y predecible.
Variable not found
Enlaces interesantes 641
marzo 16, 2026 07:02

Esta semana me he topado con bastantes contenidos interesantes 😊
Por citar algunos, ya tenemos aquí la segunda preview de .NET 11, con novedades interesantes como el runtime asíncrono, soporte nativo para trazas alineadas con OpenTelemetry, mejorillas en Blazor, soporte para OpenAPI 3.2.0, nuevas plantillas de proyecto, mejoras en rendimiento y más. Si quieres conocer todos los detalles, no te pierdas el anuncio oficial.
Bipin Joshi nos habla de las Minimal APIs una vez pasó el hype inicial: qué nos aportan, las ventajas e inconvenientes de su ausencia de código ceremonial y sus escenarios de uso ideales.
Gurveer Arora continúa exprimiendo el potencial de HTML y CSS con su serie NoJS, y en esta ocasión nos trae un clon de Flappy Bird hecho sin una sola línea de JavaScript. Porque poderse, se puede.
También me ha parecido interesante la lectura de The WebAssembly Component Model, una arquitectura para la construcción de librerías y aplicaciones interoperables utilizando WebAssembly.
Y Ricardo Peres continúa explorando las APIs de sincronización en .NET, y en esta ocasión nos habla de las herramientas que tenemos a nuestra disposición para sincronizar distintos procesos, como Mutex, Semaphore y EventWaitHandle.
El resto de enlaces, a continuación.
Por si te lo perdiste...
- ¡Cuidado con las excepciones no controladas de servicios en segundo plano (BackgroundService) en ASP.NET Core!
José M. Aguilar - Antipatrones de asincronía en C#
José M. Aguilar
.NET
- .NET 11 Preview 2 is now available!
.NET Team - Splitting the NetEscapades.EnumGenerators packages: the road to a stable release
Andrew Lock - FullJoin in .NET 11
Steven Giesel - .NET Synchronisation APIs - Part 2 - Out-of-Process Synchronisation
Ricardo Peres
ASP.NET Core / ASP.NET / Blazor
- Minimal APIs: Fix missing OpenAPI response documentation
David Grace - How to Create Fillable PDF Forms in C# for Server-Side .NET Apps
Arun Kumar Chandrakesan - How to use refresh tokens in ASP.NET Core
Joydip Kanjilal - Secure a C# MCP Server with Auth0
Andrea Chiarelli - Minimal APIs After the Hype: What Remains When Boilerplate Is Gone?
Bipin Joshi
Azure / Cloud
- Invite Guest users in a Entra ID Multi-tenant setup
Damien Bowden - Protecting Against Concurrent Updates in Azure Blob Storage with ETags
Mark Heath
Conceptos / Patrones / Buenas prácticas
- Querying and Performing Transactions Across Multiple Database Schemas in a Modular Monolith
Anton Martyniuk - Nobody Runs Your Cleanup Script (And Regulators Know It)
Martin Stühmer - Async Does Not Mean Scalable
Irina Scurtu - Your Stack Traces Are Love Letters to Attackers
Martin Stühmer - 5 Architecture Tests You Should Add to Your .NET Projects
Milan Jovanović - Vertical Slices doesn’t mean “Share Nothing”
Derek Comartin
Data
- EF Core: tu query funciona, tus pruebas pasan… y estás leyendo 50,000 filas para devolver 3
Isaac Ojeda - SQL Server TempDB: What it is and how it works
M. A. A. Mehedi Hasan - IDENTITY vs SEQUENCE in SQL Server - which should you use?
Greg Low - SQL String Functions for Data Transformation
Muhammad Hassan Arshad - Fixing SQL Server 2025 LocalDB in Visual Studio 2026: Enabling REGEXP and VECTOR Support
Erik Ejlskov Jensen
Machine learning / IA
- El nuevo paradigma de la Ingeniería de Software con IA
Juan Irigoyen - MCP Vulnerabilities Every Developer Should Know
Composio - Build a real-world example with Microsoft Agent Framework, Microsoft Foundry, MCP and Aspire
Justin Yoo - Quadratic Regression with SGD Training Using JavaScript
James McCaffrey
Web / HTML / CSS / Javascript
- Source Maps: Shipping Features Through Standards
Jon Kuperman - Abusing Customizable Selects
Patrick Brosset - Temporal: The 9-Year Journey to Fix Time in JavaScript
Jason Williams - The Value of z-index
Amit Sheen - Form-Associated Custom Elements in Practice
Rob Levin - The Enforced Accessibility of the Geolocation Element
Chris Coyier - The WebAssembly Component Model
Bytecode Alliance - Beyond border-radius: What The CSS corner-shape Property Unlocks For Everyday UI
Brecht De Ruyte - Vite 8.0 is out!
Vite Team - Moving From Moment.js To The JS Temporal API
Joe Attardi - Make custom elements behave with scoped registries
Jayson Chen & Patrick Brosset - Using CSS animations as state machines to remember focus and hover states with CSS only
Patrick Brosset - NoJS 3 - The dawn of Flappy Bird. Making a Flappy Bird clone using pure HTML and CSS, no JavaScript
Gurveer Arora - The Web’s Most Tolerated Feature
Mike Pennisi
Visual Studio / Complementos / Herramientas
- Kubernetes soluciona el caos de la programación de pods con su nuevo controlador de nodos
CampusMVP - Mi configuración de Dev Container para desarrollar plugins de WordPress
Gisela Torres - Extend your coding agent with .NET Skills
Tim Heuer - Modernize .NET Anywhere with GitHub Copilot
Mika Dumont - Configuring Claude Code for Real .NET Projects
Matt Mattei
.NET MAUI
- Build a Profile Picture Editor in .NET MAUI with the Image Editor
Karthick Mani - 5 UX Tips for .NET MAUI Developers
Leomaris Reyes
Publicado en Variable not found.
Navegapolis
Scrum en la era de la IA: la síntesis que viene
marzo 15, 2026 04:37
Nonaka y Takeuchi —que además de ser referentes en gestión del conocimiento, fueron quienes sembraron el concepto de Scrum en los años 80— describieron que el conocimiento evoluciona en espiral: una tesis funciona hasta que un cambio de contexto genera una antítesis, y de la tensión entre ambas nace una síntesis que integra lo mejor de las dos.
Scrum nació como síntesis de nuevo conocimiento al cuestionar el modelo de desarrollo en cascada de los años 80, mejorándolo con iteraciones cortas, equipos autónomos y entrega incremental.
Ahora el modelo de desarrollo vuelve a cambiar: la IA comprime ciclos, reconfigura equipos y cambia la forma de definir lo que queremos que construir. La espiral del conocimiento sigue girando: el marco inicial de scrum pasa a ser la tesis, la IA plantea la antítesis, y ya está tomando forma la nueva síntesis.
En este post intento de esbozar esta «síntesis»; no como una receta cerrada, sino dibujando el mapa de las zonas en las que la comunidad profesional ya está experimentando con evoluciones prácticas.
El sprint: más corto, más flexible, pero no prescindible
La cadencia de dos semanas ha sido el estándar de facto durante años, pero hay que recordar que no siempre fue así: las primeras iteraciones de scrum usaban ciclos de uno o dos meses. Fue la propia comunidad la que fue acortando la cadencia a medida que el contexto lo pedía. Con la IA, ese contexto ha cambiado otra vez: hay equipos que generan incrementos funcionales en días o incluso horas.
¿Significa esto que el sprint ya no sirve? No exactamente, el principio de trabajar en ciclos con puntos de inspección y adaptación sigue siendo esencial, lo que tenemos que cambiar es la duración y el formato.
Lo que está funcionando en equipos que ya trabajan con IA:
Micro-iteraciones dentro del sprint. El sprint se mantiene como contenedor de planificación y revisión estratégica, pero dentro de él el equipo ejecuta múltiples ciclos cortos de ideación-generación-validación con IA. El sprint se enriquece con un ritmo interno más rápido.
Sprints más cortos. Una semana o incluso menos, acercando la cadencia a la velocidad real de entrega.
Cadencia dual. Un ritmo rápido para exploración y prototipado (días) y otro más pausado para ingeniería de producción y validación (semanas). Esto conecta con un modelo emergente de «doble carril».
Se siguen manteniendo los momentos de reflexión. La retrospectiva es ahora más necesaria que nunca: los equipos están aprendiendo a trabajar con una tecnología nueva y necesitan espacios para evaluar qué funciona y qué no. Paradójicamente, es la velocidad de la IA la que hace más necesaria la pausa para pensar.
Equipos más pequeños, pero no sin estructura
La IA permite que equipos más reducidos logren lo que antes requería equipos grandes. La investigación de Harvard Business School (Dell’Acqua et al., 2025) afirma que equipos de 2-3 personas con asistencia de IA están consiguiendo resultados que antes requerían 7-10.
Cuando el equipo tiene como mucho 4 personas y la «voz» de una IA, algunas evoluciones que tienen sentido son:
- La daily puede transformarse en un check-in ligero, quizás asíncrono. En un equipo de dos o tres personas que se ven continuamente, una reunión formal de 15 minutos es desproporcionada.
- La planning puede simplificarse a una sesión de priorización y definición de especificaciones para la IA.
- La retrospectiva mantiene su valor pleno —quizás más que nunca— como espacio para evaluar cómo está funcionando la colaboración humanos+IA.
La idea no es eliminar eventos sino ajustar su peso al tamaño y la naturaleza del equipo. Algo que, por cierto, la agilidad siempre ha animado a hacer.
De las historias de usuario a las especificaciones (sin volver a la cascada)
Las historias de usuario son un medio de comunicación entre personas: «Como [usuario], quiero [acción] para [beneficio]». Son excelentes para transmitir intención. Pero cuando el interlocutor es una IA generativa, la intención no basta: la IA necesita contexto técnico, restricciones explícitas y criterios verificables.
Aquí entra una práctica que está ganando tracción: el Spec-Driven Development (SDD). La idea es que especificaciones detalladas se convierten en el artefacto del que la IA deriva código. Herramientas como GitHub Spec Kit ya formalizan este flujo: se describe qué se quiere construir, el agente genera una spec detallada, propone un plan, lo descompone en tareas y las ejecuta mientras el desarrollador revisa cambios focalizados.
La clave, y esto es importante, es no sustituir la historia por la spec sino relacionarlas en convivencia. La historia de usuario sigue es valiosa para capturar la intención y el contexto de negocio. La spec traduce esa intención a un lenguaje que la IA puede procesar. Y las specs deben ser documentos vivos que iteran como un backlog: se refinan, se adaptan, evolucionan.
Hay un riesgo aquí que vale la pena nombrar: si las especificaciones se vuelven rígidas y exhaustivas, podemos regresar al modelo de cascada sin darnos cuenta. La solución es tratar la spec como documentación operativa, no como un contrato inamovible. Es el lenguaje común entre humanos e IA, no burocracia.
Los roles: evolución.
Product Owner → Product Architect
Cuando la IA puede construir features más rápido de lo que la organización puede validar si son las correctas, el Product Owner se convierte en el factor limitante de la cadena de valor. Y eso, lejos de restarle importancia, se la multiplica.
Su evolución natural es hacia un Product Architect cuyo foco se desplaza de gestionar un backlog a ser el constructor de la decisión estratética: ¿qué se debe construir? Esto requiere competencias nuevas —data literacy, diseño de experimentos de validación, gestión de la tensión entre velocidad de producción y ritmo de validación—, la esencia del rol sigue siendo: maximizar el valor del producto.
Scrum Master → Agile Enabler
Quizá el rol donde más claridad se necesita. Lo que evoluciona no es la necesidad de alguien que facilite cómo trabaja el equipo, sino el alcance y la naturaleza de esa facilitación.
Cuando el equipo era un grupo de 7 personas, facilitar significaba sobre todo coordinar interacciones, eliminar impedimentos y proteger el espacio del equipo. Cuando el equipo es un sistema de 2-3 personas orquestando a agentes de IA, facilitar significa algo bastante más amplio:
Diseñar flujos de colaboración híbridos. ¿Cómo se divide el trabajo entre humanos e IA? ¿Estamos dando a la IA el contexto suficiente? ¿Revisamos sus outputs con el rigor adecuado? Alguien tiene que facilitar estas preguntas y optimizar estos flujos.
Gobernanza ética y de calidad. ¿Quién rinde cuentas cuando un agente comete un error? ¿Cómo gestionamos los sesgos? ¿Qué políticas de uso necesitamos? El facilitador ayuda al equipo a desarrollar estas políticas como práctica viva, no como imposición burocrática.
Gestión de la confianza. Los datos muestran desconfianza de los desarrolladores en el código o trabajo generado por IA. El facilitador ayuda a construir una relación sana con la IA: ni confianza ciega ni desconfianza paralizante. Esto requiere las mismas competencias de inteligencia emocional que siempre definieron al buen Scrum Master, aplicadas a un contexto nuevo.
Coaching del cambio. La transición hacia equipos potenciados con IA no es solo técnica: es cultural. Hay resistencias, curvas de aprendizaje desiguales y dinámicas que cambian cuando la IA redistribuye capacidades. Facilitar esa transición es trabajo de un profesional experimentado en dinámicas humanas.
Pensamiento sistémico. El facilitador evolucionado no ve eventos aislados sino el sistema completo: cómo fluye el trabajo, dónde se generan cuellos de botella, cómo interactúan los loops de feedback y qué consecuencias no intencionadas produce el uso de IA.
En resumen: el Scrum Master se transforma en alguien que facilita sistemas de trabajo más complejos, donde la complejidad no viene solo de las personas sino de la interacción entre personas e inteligencias artificiales.
Developers → Product Builders
El equipo de desarrollo evoluciona hacia perfiles que combinan herramientas no-code, generación de código asistida por IA y comprensión profunda del producto. Su valor se desplaza desde la implementación hacia la orquestación: diseñar arquitecturas, escribir especificaciones, revisar lo que la IA genera y asegurar estándares de calidad.

Calidad: el frente donde más atención hace falta
Este es posiblemente el punto más delicado de toda la evolución. Los datos invitan a la prudencia: sin controles deliberados, la IA acelera la acumulación de deuda técnica. El equipo va más rápido, pero el código puede volverse frágil y costoso de mantener.
Las prácticas que están emergiendo como respuesta son sensatas y pragmáticas:
- IA supervisando IA: una IA como revisora automática de lo que otra genera, con semáforos y revisiones automatizadas.
- Specification by Example: tests con especificaciones concretas y verificables. La IA no puede corregir sus propios deberes.
- Definition of Done reforzada: adaptada para código generado por IA, incluyendo revisiones de seguridad, análisis estático y verificación de no-duplicación.
- Auditoría continua de deuda técnica: monitorización activa de métricas de salud del código como contrapeso a la velocidad.
Aquí es donde los principios de inspección y adaptación se vuelven, si cabe, más necesarios. La velocidad sin validación es desperdicio.
Dos incorporaciones emergentes que vale la pena conocer
El Doble Carril (Double-Track)
Un carril rápido (Vibe Coding) para crear prototipos no liberables a producción, validar ideas rápidamente usando IA y no-code. Aquí la calidad del código es secundaria; lo que importa es la velocidad de aprendizaje.
Un carril robusto (Vibe Engineering) que asegura estándares de ingeniería, seguridad y calidad para lo que va a producción. Aquí se aplican SDD, Definition of Done reforzada y QA.
La separación entre carriles no es nueva —el dual-track agile existe desde hace años—, pero la IA la hace más explícita y necesaria. La velocidad del carril rápido puede ser 10x-100x mayor que la del robusto, lo que exige gestión consciente de cuándo una idea pasa de uno a otro.
IA como Teammate
El framework de Scrum.org propone cuatro pasos para integrar la IA como compañero de equipo: selección de modelos, provisión de contexto, prompt engineering y gobernanza. Es un enfoque más conservador, directamente compatible con Scrum actual y adoptable de forma incremental. Un buen punto de partida para equipos que están empezando.
La espiral sigue girando
Scrum es conocimiento abierto. No es un modelo «propietario» que tenga una definición en exclusividad. Emergió desde abajo, construido por la comunidad profesional, y así ha evolucionado siempre: los sprints se acortaron, las retrospectivas se generalizaron, el refinamiento del backlog se formalizó.
La integración de la IA es el siguiente capítulo natural de esa evolución. Los equipos ya están experimentando con nuevas formas de trabajar. Algunas se están articulando como prácticas emergentes. La síntesis está en construcción.
No hay que esperar a que nadie nos dé permiso. Es lo que siempre hemos hecho.
La entrada Scrum en la era de la IA: la síntesis que viene se publicó primero en Navegápolis.
Picando Código
Reseña: Vultures - Scavengers of Death - Steam
marzo 11, 2026 09:00

Vultures - Scavengers of Death es un juego de survival horror por turnos, con inspiración en clásicos como Resident Evil y Parasite Eve. Los gráficos están estilizados como recuerdo el primer Resident Evil en PlayStation. Se ven bastante poligonales, pero optimizados para pantallas modernas con alta definición. Manteniendo una personalidad retro, con las ventajas que traen muchos años de experiencia y avances tecnológicos en videojuegos.
Me gusta que se aprecie el estilo creado a partir de las limitaciones de hardware de tiempos anteriores. Sobretodo cuando hoy hay mucho menos limitaciones tecnológicas. En materia creativa a veces los límites fomentan la creatividad, y se generan expresiones gráficas clásicas que no pierden vigencia, como ésta. Por cierto, Resident Evil cumple 30 años el próximo Domingo 22 de marzo.
Mi experiencia con Resident Evil es muy reducida. Recuerdo haberlo jugado una vez que fui a la casa del amigo de un amigo donde había un PlayStation 1 conectado a un televisor CRT de 14 o 21 pulgadas. Éramos varios charlando mientras nos íbamos turnando para jugar un poco. Qué buenos tiempos aquellos de adolescente donde andaba callejeando por Maldonado y terminábamos jugando PlayStation en un apartamento y esa memoria vendría a mi cabeza décadas más tarde para reseñar un juego.
En Vultures - Scavengers of Death, la ciudad colapsó tras una explosión en un centro industrial que transformó a la población en zombis. En una metrópolis sellada bajo cuarentena total, asumimos el rol de un agente de la unidad de mercenarios VULTURES. Fuimos contratados para alcanzar la cima de la torre Nakat... Eugenesys y con suerte encontrar una cura.
El juego tiene esa característica opresiva del horror de supervivencia que tenemos que gestionar bien los recursos. La munición es limitada y no tenemos un amplio arsenal de armas para entrar cuarto por cuarto eliminando zombies a diestra y siniestra. También necesitamos recurrir a la estrategia, porque tirarnos de frente contra todo enemigo que nos encontremos no nos va a ayudar a progresar. Los desarrolladores comentaron que tuvieron en cuenta éstos factores, fundamentales en los géneros que combina, a la hora de diseñar armas y equipamiento.
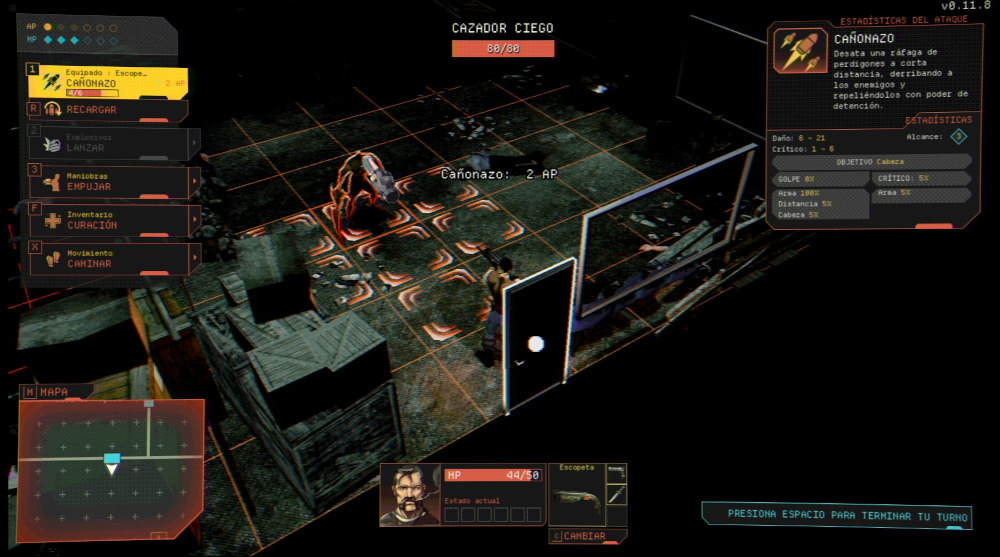
El cazador ciego, una de las "criaturas" de Vultures - Scavengers of Death
Un aspecto particular que puede sonar raro si conocemos los títulos en los que está inspirado, es el combate por turnos. No sé si ya se había hecho un juego así con aspectos de horror de supervivencia. Pero me resultó diferente e interesante. Los desarrolladores hablan bastante del tema en la página de Steam. Ese post en particular nos aporta un montón de información sobre las características del juego y cómo llegaron a ellas.
Su idea es permitirnos tiempo para pensar qué hacer en cada situación, pero también ofrecer algo poco convencional dentro del género. A lo que tenemos acciones limitadas y tiempo, podemos evaluar las opciones y armar una estrategia. Citan a Breach, Colony Ship, Xcom, y Dungeon and Dragons como inspiración para el combate. Todo surgió de hacer un roguelike a lo Resident Evil en una terminal retro de los 80, usando comandos de texto. Así destilaron las mecánicas clave de survival horror y las tradujeron al contexto de un juego de tablero.
Agregan también que consideraron tener niveles generados procedimentalmente. Pero llegaron a la conclusión que no era la mejor opción. Su explicación me parece muy buena, pueden leerla en el enlace anterior.
Estoy de acuerdo que si bien generar los escenarios es técnicamente viable (y en algunos casos agrega mucha variedad), para cierto tipo de juegos es difícil lograr el balance y sensaciones adecuado. Personalmente prefiero algo más "curado", como esto, donde los desarrolladores tienen que definir cada nivel, jugarlo y ver cómo se siente. De repente queda esa opción para más adelante.
El juego está hecho con Godot, el motor de desarrollo de videojuegos multiplataforma software libre. Me encanta ver juegos de calidad hechos con Godot. Está muy bueno ver la variedad de estilos y mecánicas que se pueden lograr con esta herramienta. Ya he comentado que estuve experimentando y desarrollando un poco con Godot, y me gustó bastante lo que pude lograr con relativamente poco estudio y experimentación. Voy a ver si en algún momento vuelvo.
¡Es un juego Colombiano! Está desarrollado por Vultures Team: Mateo y Giovanni son amigos y compañeros con más de nueve años de trayectoria creando juegos y software juntos. Destacan por desarrollar mecánicas experimentales y adoptar un estilo artístico retro y poco convencional. En ocasiones, sus juegos incorporan toques de crítica social y política, cuestionando a menudo la sociedad de consumo y el capitalismo desenfrenado.
He estado jugando la demo en Steam, disponible en varios idiomas incluido el Español. Podemos jugar con Leopoldo, uno de los (al menos dos) personajes disponibles e incluye completa la primera misión.
Nos encontramos en una jefatura de policía, donde irán apareciendo los primeros zombis. La mayoría son oficiales de policía, y los podemos atacar con una pistola, un cuchillo y cócteles molotov. Más adelante podemos obtener una escopeta, que ataca más de un espacio a la vez y empuja a los enemigos. Ideal cuando tenemos un grupo de zombis enfrente.
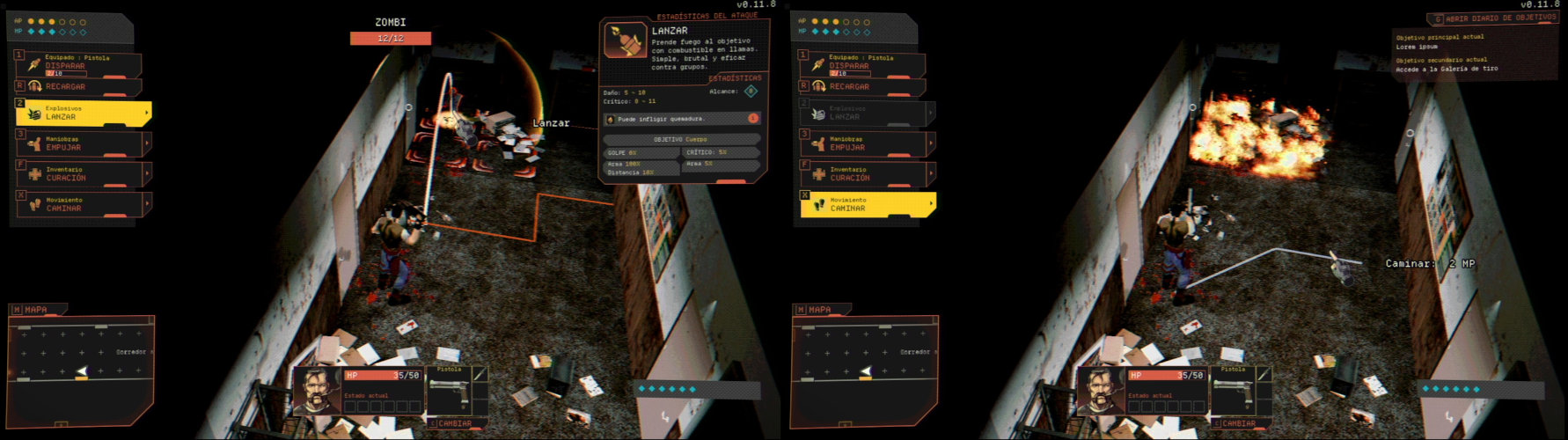
¡Fuego! ¡Fuego al zombi policía! Mujajajajaja... El molotov es más efectivo para atacar más de un zombi, pero necesitaba probarlo.
A medida que vamos jugando, vamos desbloqueando cosas y se va poniendo más interesante. Las primeras pocas veces que jugué el demo, no lograba engancharme. Moría relativamente rápido y no avanzaba mucho. Pero con unas pocas jugadas más le fui agarrando la mano y disfrutándolo más. Son importantes las palabras de sus desarrolladores sobre la estrategia. Es mejor tomarse un tiempo y ver qué opciones tenemos, que ir adelante y atacar. Cuando lo enfrentaba como un juego de acción, generalmente terminaba viendo la pantalla de partida perdida. Por suerte cuando perdemos, si decidimos continuar, empezamos en la última puerta que atravesamos.
Para ayudar nuestro progreso, vamos a ir encontrando cosas útiles en el camino. Los botiquines de primeros auxilios los podemos usar para curar al personaje, hay computadoras para guardar el progreso y dispensadores de agua que también recuperan un poco de salud.
Nos podemos mover libremente por la grilla de cada cuarto, pero si un zombi nos detecta, entramos en modo combate. En el modo combate tenemos puntos de acción y movimiento limitados para realizar acciones de ataque, movernos, cambiar de lugar con un enemigo, empujar, curarnos y más.
A la hora de explorar, podemos elegir entre tres modos para desplazarnos: caminar, correr y sigilio. A medida que avanzamos aprendemos lo importante de ir usando cada uno. Cuando volvemos por cuartos que sabemos son seguros, o recorremos pasillos, vamos a querer ir corriendo. Luego en general caminando, pero el sigilio va a ser un arma casi que imprescindible. No sólo nos permite evitar la detección por los zombis, también podemos hacer ataques estratégicos. Es importante tener en cuenta la posición y las ventajas que podemos conseguir para evitar que nos dañen. O directamente podemos evitar totalmente el combate, para ahorrar balas y energía.

En esta habitación perdí por enfrentarme a todos los zombies a la vez. Con sigilio me pude ir acercando de a poco a cada uno y apuñalarlos antes que me vieran, dándome un ataque de ventaja. También, las mesas están en posiciones que nos permiten ocultarnos o definir por dónde se van a mover los zombies si nos atacan.
La historia se va a ir descubriendo interactivamente por medio de documentos y otros ítems que revelan qué pasó. Asimismo recolectamos llaves o pistas para abrir distintas puertas que en principio se encuentran bloqueadas. Me resultó imprescindible usar el mouse y teclado a la vez. Se podría jugar sólo con el mouse, pero resulta mucho más práctico ir aprendiéndose los atajos de teclado para cambiar el modo de caminata, el arma, etc. ágilmente.
La demo lleva entre 40 y 50 minutos de juego promedio. Termina cuando llegamos al final del primer nivel en la jefatura. Hicieron un buen trabajo con esto último, la historia se va desenvolviendo y se pone interesante a medida que avanzamos. Para cerrar, vemos que al igual que en Resident Evil, no van a ser sólo zombies los monstruos sueltos. Recomiendo probar la demo, sobretodo si te gusta cualquiera de los títulos nombrados como inspiración. Y ya se puede agregar a la Wishlist de Steam si te interesa.
El juego completo está planeado publicarse en Abril de 2026. Incluirá más niveles y a Amber, una mercenaria aparentemente inspirada en Motoko Kusanagi. Se destaca por sus movimientos rápidos y sigilosos, y cuenta con un gameplay distintivo. Está disponible en Steam para Windows, pero me funcionó perfectamente en Garuda Linux con Proton 10.0.4. Está hecho en Godot, así que salvo que tenga algún componente exclusivo para Windows, de repente el juego completo tiene una versión nativa para Linux.

El post Reseña: Vultures - Scavengers of Death - Steam fue publicado originalmente en Picando Código.
Variable not found
Enlaces interesantes 640
marzo 09, 2026 07:05

Ya he publicado los enlaces a contenidos interesantes que he ido descubriendo a lo largo de la semana pasada 😊
En esta entrega, destacamos el repaso de Martin Stühmer a los errores más comunes en la gestión de sesiones en aplicaciones ASP.NET Core y cómo evitarlos para mejorar su seguridad de nuestras aplicaciones.
Se ha lanzado la versión 1.0 del SDK oficial de MCP para C#. Aún no he tenido tiempo de probarlo, pero así al vistazo parece que puede facilitarnos un poco la vida a la hora de integrar nuestras aplicaciones con modelos de lenguaje y otros servicios de IA.
Y seguimos con más lanzamientos, Jetbrains han anunciado ReSharper para Visual Studio Code, Cursor y editores compatibles. Como fan incondicional de esta herramienta desde hace años, me alegra que ahora esté también disponible más allá de Visual Studio.
Por último, Gerson Azabache nos recuerda la importancia de hacer ejercicio, especialmente para los desarrolladores, que pasamos muchas horas sentados frente al ordenador y a menudo descuidamos nuestra salud física.
Muchos más enlaces a contenidos interesantes, a continuación.
Por si te lo perdiste...
- Gestión centralizada de paquetes NuGet en soluciones y proyectos .NET
José M. Aguilar - Si las shadow properties no existen como propiedades en la entidad, ¿cómo podemos inicializarlas en el seed de Entity Framework Core?
José M. Aguilar
.NET
- Why IEnumerable Can Kill Performance in Hot Paths
Ali Hamza Ansari - Creating case-sensitive folders on Windows using C#
Gérald Barré - Writing a .NET Garbage Collector in C#
Kevin Gosse
ASP.NET Core / ASP.NET / Blazor
- YARP as API Gateway in .NET: 7 Real-World Scenarios You Should Know
Anton Martyniuk - TryParse error when using Minimal APIs
Bart Wullems - How to secure ASP.NET Core APIs with Basic Authentication
David Grace - Stop Re-Entering Your Token in Swagger UI: EnablePersistAuthorization in ASP.NET Core
Juan Luis Guerrero - Rate Limiting IdentityServer Endpoints
Maarten Balliauw - Cleaner Minimal API Endpoints with [AsParameters]
Bart Wullems - Customizing the New ReconnectModal Component in Blazor 10
Héctor Pérez - Your Logout Button Is Lying: ASP.NET Session Security Done Right
Martin Stühmer
Azure / Cloud
- Azure Trusted Signing Revisited with Dotnet Sign
Rick Strahl - Introducing GPT-5.4 in Microsoft Foundry
Naomi Moneypenny
Conceptos / Patrones / Buenas prácticas
- When to Use Factory Method Pattern in C#: Decision Guide with Examples & Prototype Design Pattern in C#: Complete Guide with Examples
Nick Cosentino - Fencing Tokens and Generation Clock in .NET: Stop Zombie Leaders From Writing
Chris Woodruff
Data
- How C# Strings Silently Kill Your SQL Server Indexes in Dapper
Kevin W. Griffin - Managing multiple SQL Server instances from SQL Server Management Studio
Bart Wullems
Machine learning / IA
- GPT-5.3 Instant: conversaciones cotidianas más fluidas y útiles & Introducing GPT-5.4
OpenAI - Decision Trees
Jared Wilber & Lucía Santamaría - So whats the next word, then?
Matthias Kainer - Give Your Agents Domain Expertise with Agent Skills in Microsoft Agent Framework
Sergey Menshykh - Release v1.0 of the official MCP C# SDK
Mike Kistler - Model Context Protocol (MCP): Building AI Integrations in .NET Using the C# SDK
Arulraj Aboorvasamy - MicrosoftDocs/Agent-Skills: Curated Agent Skills for Microsoft & Azure – giving AI coding assistants structured, real-time expertise from Microsoft Learn docs
Microsoft
Web / HTML / CSS / Javascript
- TanStack Query en Angular: caché y rendimiento
David Filipe Lopes - Announcing TypeScript 6.0 RC
Daniel Rosenwasser - Popover API or Dialog API: Which to Choose?
Zell Liew - Navigation API - a better way to navigate, is now Baseline Newly Available
Ray Rungta - The Odometer Effect (without JavaScript)
Preethi Sam - New to the web platform in February
Rachel Andrew - Quick tip: hosting HTML/CSS/JS demos from source code on GitHub Pages
Christian Heilmann - You can use newline characters in URLs
Daniel Lemire - Security Advisory: Addressing Recent Vulnerabilities in Angular
Angular Team - Sticky Grid Scroll: Building a Scroll-Driven Animated Grid
Theo Plawinski - Singleton or Not? Understanding Angular Services
Dhananjay Kumar - The Different Ways to Select <html> in CSS
Daniel Schwarz - The Big Gotcha of Anchor Positioning
Chris Coyier
Visual Studio / Complementos / Herramientas
- From idea to pull request: A practical guide to building with GitHub Copilot CLI
Ari LiVigni - ClockTray – Hide or Show Your Windows Clock with One Click (yes, in C#)
Bruno Capuano - ReSharper for Visual Studio Code, Cursor, and Compatible Editors Is Out
Sasha Ivanova & Alexander Kurakin
.NET MAUI
- How to Stream Real-Time Data into a .NET MAUI DataGrid Using Firebase
Shalini Suresh - .NET 10: Secondary Toolbar Items for iOS, macOS in .NET MAUI
Leomaris Reyes
Otros
- ¿Quieres programar mejor? Empieza por entrenar tu cuerpo
Gerson Azabache Martínez - Crawling a billion web pages in just over 24 hours
Andrew Chan
Publicado en Variable not found.
Variable not found
C# bizarro, episodio 7: crisis de identidad
marzo 06, 2026 03:38

Vamos con una entrega más (siete llevamos ya) de la serie C# bizarro, estos divertidos posts donde ponemos a prueba nuestros conocimientos del lenguaje mientras exploramos algunas de sus características extrañas o poco conocidas.
En esta ocasión, os propongo que le echéis un vistazo al siguiente código, en especial a su método ChangeIdentity(), que pretende cambiar la identidad de una persona por la de otra que le llega como parámetro:
var john = new Person() { Name = "John" };
var peter = new Person() { Name = "Peter" };
john.ChangeIdentity(peter);
Console.WriteLine(john.Equals(peter));
struct Person
{
public string Name;
public void ChangeIdentity(Person otherPerson)
{
this = otherPerson; // WFT!?!?
}
}
En efecto, en el cuerpo del método estamos asignando un nuevo valor a this. ¿Pensáis que esto compilará? Y en caso afirmativo, ¿qué veríamos en la consola al ejecutarlo, true o false?
El código, efectivamente, compila sin problema. Aunque la asignación de this pueda parecer extraña, es perfectamente válida en C# porque estamos en el interior del método de instancia de una estructura. No compilaría, en cambio, si Person fuera una clase.
Esto se debe a que internamente las estructuras son tipos valor, por lo que this representa una copia completa del valor de la estructura en memoria. Al asignar this = otherPerson, estamos copiando el valor de otherPerson sobre this, lo que en la práctica significa que estamos copiando el valor de todos los campos de la estructura origen sobre la actual, aunque sin tener que hacerlo de forma manual 🙂
En clases, sin embargo, this es una referencia (o puntero) inmutable a la instancia del objeto en memoria, por lo que no se puede reasignar para ponerla apuntando a otro objeto.
Ahora vamos con la segunda parte de la pregunta, ¿qué veremos en la consola al ejecutar el código que utiliza el método ChangeIdentity()?
var john = new Person() { Name = "John" };
var peter = new Person() { Name = "Peter" };
john.ChangeIdentity(peter);
Console.WriteLine(john.Equals(peter));
Seguro que habéis adivinado que la respuesta es true. Fijaos que si hubiésemos utilizado clases en lugar de estructuras, el resultado habría sido false, ya que john y peter serían punteros a objetos distintos en memoria y la igualdad por referencia nunca sería cierta. Pero al ser estructuras, la comprobación de igualdad se realiza por valor, es decir, comparando los valores de todos sus campos.
Y dado que anteriormente hemos copiado los valores de todos los campos de peter sobre la estructura john, ambos objetos son idénticos en memoria y, por tanto, la operación de comparación devuelve true.
Qué, ¿lo habíais adivinado? 😄
Publicado en Variable not found.
Navegapolis
Legado digital
marzo 05, 2026 12:09
Explorando cómo programar con IA, el episodio “La muerte digital” del podcast DECODE de Dani Sánchez-Crespo (DaniNovarama) me dio la idea de hacer un programa para el reto que plantea: ¿qué pasa con tus contraseñas, seguros, accesos bancarios y documentos privados si un día no estás? ¿Cómo puede acceder tu familia?
Así que aprovechando la fiesta del 5 de marzo (para eso hay que ser de Zaragoza  )este es el resultado: Legado Digital: un único ejecutable que se puede guardar en un pendrive, sin instalación. Almacena la información cifrada con AES-256-GCM y Argon2id.
)este es el resultado: Legado Digital: un único ejecutable que se puede guardar en un pendrive, sin instalación. Almacena la información cifrada con AES-256-GCM y Argon2id.
Esta es la información de lo que he usado, y la aplicación, por si os puede ser útil:
He usado:
- Antigravity coon Gemini3.1 Pro.
- Go para el motor de seguridad.
- base de datos SQLite (en memoria)
- Svelte + TailwindCSS para la interfaz
- Wails v2 para empaquetarlo todo en un único binario de Windows.
El programa lo podéis descargar en el enlace de abajo que tiene el ejecutable y un txt de instrucciones, que comparto tal cual, sin compromisos de licencia ni mantenimiento para los que os pueda resulta útil.
La entrada Legado digital se publicó primero en Navegápolis.
Variable not found
Enlaces interesantes 639
marzo 02, 2026 07:01

Una semana más, vamos con los enlaces a contenidos interesantes que he ido recopilando durante estos días, entre los que destaco algunos posts.
Juan Irigoyen comparte sus experiencias utilizando IA para optimizar SQL Server, en un interesante recorrido por la preparación de un agente Claude capaz de analizar y optimizar consultas SQL, con resultados bastante prometedores.
La depuración puede ser una labor compleja, intensa, a veces frustrante y otras gratificante, pero sin duda forma parte de nuestro día a día. En este artículo, Jeremy D. Miller reflexiona sobre el proceso de depuración, compartiendo consejos para abordar los problemas de manera efectiva-
Y para terminar, una frikada épica a la que llego a través de Microsiervos: un procesador x86 completo implementado únicamente con CSS, sin una sola línea de código JavaScript, y que es capaz de ejecutar código ensamblador compilado para ese procesador.
El resto de contenidos interesantes, a continuación.
Por si te lo perdiste...
- Trocear predicados para mejorar la legibilidad
José M. Aguilar - Shadow properties en Entity Framework Core
José M. Aguilar
.NET
- Logging Profesional en .NET con Serilog: Minimalismo Bien Hecho
Gerson Azabache Martínez - When to Use Builder Pattern in C#: Decision Guide with Examples
Nick Cosentino - A smarter way to learn .NET without reading the docs
David Grace - .NET 11 Preview 1 Arrives with Runtime Async, Zstandard Support, and C# 15 Features
Almir Vuk - Recording metrics in-process using MeterListener
Andrew Lock - Cleaner switch expressions with pattern matching in C#
Bart Wullems - Vector Data in .NET - Building Blocks for AI Part 2
Jeremy Likness - Is it faster to index into an array or use switch statement for lookups?
Jiří Činčura - Semantic Kernel in C#: Complete AI Orchestration Guide
Nick Cosentino - .NET Synchronisation APIs - Part 1
Ricardo Peres - Brave new C#
PVS-Studio - Developing an MCP Server with C#: A Complete Guide
NDepend Team
ASP.NET Core / ASP.NET / Blazor
- Cookie Banners Won't Save You From ISO 27701
Martin Stühmer - Stop Wrestling with JavaScript: htmxRazor Gives ASP.NET Core the Component Library It Deserves
Chris Woodruff
Azure / Cloud
- How to Troubleshoot Azure Functions Not Visible in Azure Portal
Vikas Gupta - Optimising AI Costs with Microsoft Foundry Model Router
Lee Stott
Conceptos / Patrones / Buenas prácticas
- Rename, para entender mejor
Fran Iglesias - Read Replicas Are NOT CQRS (Stop Confusing This)
Peter Ritchie - How to Avoid Code Duplication in Vertical Slice Architecture in .NET
Anton Martyniuk - TDD as induction
Mark Seemann - On Debugging Problems
Jeremy D. Miller
Data
- Optimización en Sql Server usando IA
Juan Irigoyen - Emulating GETDATE() on Azure SQL Database
Joe Obbish - Polymorphic Relationships in EF Core: Three Approaches
Ali Hamza Ansari - The Hidden Work Behind SELECT TOP in SQL Server
Jared Westover
Machine learning / IA
- Primeros pasos con Microsoft Agent Framework: construyendo un chatbot de soporte con C#
Isaac Ojeda - Microsoft Agent Framework is Release Candidate! Let’s Go
Bruno Capuano - Redefining the Software Engineering Profession for AI
Mark Russinovich & Scott Hanselman - [TIP] How to Add MCP Servers to Claude Code and Gemini CLI on Windows
Juan Luis Guerrero
Web / HTML / CSS / Javascript
- Playing CSS-defined animations with JavaScript
Ben Hatsor - Loading Smarter: SVG vs. Raster Loaders in Modern Web Design
Mariana Beldi - Virtual Scroll-Driven 3D Scenes
Gunnar Bachelor - Goodbye innerHTML, Hello setHTML: Stronger XSS Protection in Firefox 148 - Mozilla Hacks
Tom Schuster, Frederik Braun & Christoph Kerschbaumer - A Complete Guide to Bookmarklets
Declan Chidlow - An Exploit ... in CSS?!
Lee Meyer - A Guide to Jakob’s Law in Web Development
Adrew Peterson - React 19 Suspense for Data Fetching: A New Model for Async UI
Prashant Yadav - We deserve a better streams API for JavaScript
James M. Snell - Yet Another Way to Center an (Absolute) Element
Juan Diego Rodríguez - The Hidden Trick of Style Queries and if()
Temani Afif - Building Async Page Transitions in Vanilla JavaScript
Valentin Mor
Visual Studio / Complementos / Herramientas
- cURL para desarrolladores .NET: guía práctica, real y profesional
Gerson Azabache Martínez - GitHub Copilot CLI is now generally available
GitHub Copilot Team - The Dongle Died at Midnight – WinForms Agent Saved my German Mom's Business Trip
Klaus Loeffelmann - Introducing Agentic UI Builder: Build Complete Enterprise UIs with Syncfusion MCP Servers
Lokeshwaran Ragavan - Run OpenClaw Securely in Docker Sandboxes
Oleg Selajev - XAML.io v0.6: Share Running .NET Code With a Link
XAM.io Team - Stop Drawing Architecture Diagrams Manually: Meet the Open-Source AI Architecture Review Agents
Shivam Goyal - VS Code: Building Long-Distance Next Edit Suggestions
Vikram Duvvur, Gaurav Mittal & Benjamin Simmonds
.NET MAUI
- Simplifying Grid Layout in .NET MAUI Using Extension Methods
Leomaris Reyes - C# Expressions in XAML: throw out your converters
Steven Thewissen - How to Add Email and Toast Reminders to a .NET MAUI Scheduler
Yuvaraj Gajaraj
Otros
- What is egoless programming?
Ivan Kranjec - x86 CPU made in CSS
Lyra Rebane
Publicado en Variable not found.
Picando Código
Migrando código de GitHub a Codeberg
febrero 26, 2026 12:00
![]()
Sigo con mi migración a un uso más sano de internet, computadoras, la vida, el universo y todo lo demás. Además de estar alojando mi servidor Git con Forgejo, también empecé a migrar mis cosas de GitHub a Codeberg. Mi idea es por lo menos todos mis proyectos personales irlos borrando de GitHub. Voy a tenerlos tanto en Codeberg como mi instancia local privada de Forgejo.
Eventualmente éstos sistemas van a implementar la federación. Ahí buscaré una forma de alojar mi propia instancia en algún servidor remoto. Me gusta mucho la idea de tener una instancia propia y personal. Y desde ahí compartir mi código de manera pública y colaborar con código abierto y software libre. Haría el trabajo que hacía GitHub, pero de forma autónoma y sin el veneno de Microslop encima.
Voy bastante lento, sinceramente es un trabajo aburrido y monótono. Además después de pasar todo el día trabajando (gran parte de eso interactuando con GitHub), me quedan pocas ganas a la tarde/noche de seguir haciendo eso. Pero va saliendo.
Muchos de los repositorios los he ido compartiendo acá en el blog, así que tengo que ir buscando los enlaces para cambiarlos a su dirección nueva y guardar los posts o comentarios. Ya he cambiado algunos y borrado los repositorios enteros de GitHub. No me interesa qué registro quede en mi perfil de GitHub de lo hecho en el pasado, ya no va a ser mi perfil por defecto de código abierto en internet.
Tengo un par de cosas alojadas en GitHub Pages que voy a tener que sacar de ahí. Es todo contenido estático, así que es fácil moverlas a un servidor web común (incluso el mismo servidor donde está alojado este blog). Por cada uno tengo que buscar un hogar nuevo y cambiar dónde apunta el dominio.
El otro tema es la automatización. Las acciones de GitHub son bastante convenientes (cuando funcionan) a la hora de automatizar (excepto a la hora de querer testearlas). Creo que Codeberg tiene algo compatible con eso, pero no lo he revisado. Lo único automatizado que tengo es mi sitio web personal. Es un sitio estático generado con Middleman, pero tiene un montón de contenido que se obtiene dinámicamente. Por eso tengo una acción que actualiza el sitio automáticamente. De repente lo muevo a un servidor y programo un cron en mi Raspberry Pi para que lo genere y suba los archivos por FTP como en los viejos tiempos.
Desde que lo compró Microslop, GitHub se ha ido transformando en un producto cada vez peor. ¡Como todo lo que toca Microslop! Lamentablemente voy a tener que seguir usando GitHub, en el trabajo particularmente hacemos casi todo alrededor de GitHub. Lo cual tiene sentido, como he dicho anteriormente, mi teoría es que GitHub va a ser a Git lo que Jira es a gestión de proyectos. Lo van a terminar usando empresas a las que convencieron que necesitan comprar este producto para hacer desarrollo de software. También voy a mantener por ahora un mirror de mi plugin de WordPress, hasta que vea de coordinar con el otro mantenedor para mudarlo a Codeberg.
Además de todos los problemas éticos que tengo con GitHub, la aplicación está cada día está más inusable. Leí algo de que lo llenaron de React y esto hace que todas las interacciones sean lentas y poco confiables. Además Microslop viene acosándonos con Clippy (ahora con el nombre de copiloto) cada vez más. Esta gente no entiende que no es no.
Cualquier proyecto personal nuevo de código abierto en el que trabaje ya lo voy a tener alojado directamente en Codeberg, pero mientras sigo lentamente migrando de a pocos proyectos por semana...
El post Migrando código de GitHub a Codeberg fue publicado originalmente en Picando Código.Picando Código
Reus 2 + DLC Praderas - Steam
febrero 19, 2026 07:00

Uno es el universo, eterno, sólo, aburrido. Hasta que una chispa de vida se manifiesta a través de muchas voces con el nombre de Humanidad. Son ambiciosos y acuden a ti buscando ayuda, te llaman Naturaleza. Motivado por su creatividad, creas gigantes elementales que te ayuden a darle forma al mundo. Ayudando a los humanos con sus ambiciones, comienza un nuevo capítulo para proveeer de vida al universo.
Con esta introducción majestuosa comienza la aventura en Reus 2, un juego de estrategia y simulación que nos pone en el lugar de una deidad al mando del sistema solar. Cada partida nos presenta con un planeta desolado que tenemos que terraformar para hacer habitable. Inicialmente tenemos 3 gigantes elementales disponibles, pero a medida que avanzamos en el juego vamos habilitando gigantes nuevos. También está la posibilidad de habilitar todo desde un principio, pero en lo personal preferí ir descubriendo cada recurso nuevo a medida que juego.
Cada gigante permite terraformar un bioma distinto: océano, selva, bosque, desierto, pradera, sabana y más. A su vez, son los encargados de agregar flora, fauna y minerales al planeta. Inicialmente tenemos una tribu o grupo, pero a medida que avanzamos van a mudarse más humanos, y tenemos que crear un hábitat para cada uno. Cada bioma permite flora, fauna y minerales distintos, aunque algunos están disponibles en más de un bioma. En el océano tenemos algas, peces, en la tierra árboles con frutos como arándanos y bananas, conejos y carpinchos, entre otros.
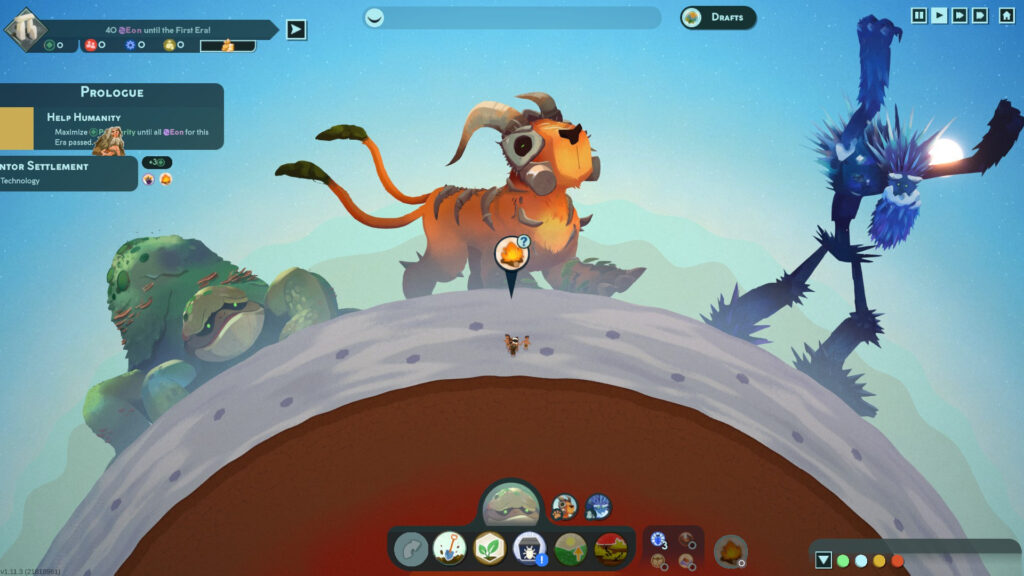
Reus 2 - Gigantes Elementales
Dependiendo de las necesidades de cada grupo humano, tenemos que equilibrar el medio ambiente con estas bióticas para proveer tecnología, riqueza, alimento y biodiversidad. Reus 2 tiene un montón de cosas por aprender. Pero el juego mismo reconoce que es imposible aprender todo al mismo tiempo, así que aconseja ir aprendiendo a nuestro tiempo. Casi todo tiene un tooltip con explicaciones. La primera misión es un tutorial que resulta bastante esencial y nos enseña lo básico. No hay que agobiarse, a medida que vamos jugando más, le vamos agarrando más la mano y aprendiendo cómo gestionar mejor el planeta.
Hay muchos factores a tener en cuenta y esto hace que sea importante la estrategia que vamos desarrollando con la experiencia. A medida que avanzamos y habilitamos nuevas características, aumenta un poco la complejidad. En algunos momentos se siente como un juego de puzzles tratando de equilibrar los distintos recursos de cada bioma para proveer a cada civilización lo que requiere para prosperar. Pero es muy entretenido y tiene ese factor adictivo de juegos de simulación similares. Es muy satisfactorio completar un planeta e ir viendo cómo avanzamos y nuestro sistema solar se va poblando de más planetas.
Está divertido el loop de empezar un planeta nuevo, jugar y avanzar en las distintas épocas hasta dar por terminado un planeta. Al final recibimos recompensas en relación a las metas que superamos y cómo ayudamos a los humanos. Podemos empezar un planeta de nuevo con lo aprendido y las especies, habilidades o hasta gigantes nuevos a probar. Esto resulta bastante liviano, y como todo juego de estrategia podemos probar cosas distintas para obtener resultados variados en cada nuevo intento.
Cuando tenemos más de un grupo de humanos, empiezan a interactuar entre sí. A veces hacen trueque y generan amistad entre ellos. Otras veces deciden atacarse o robarse recursos entre sí. En esos momentos podemos no intervenir y dejar que se peleen entre ellos. Pero también podemos despertar el espíritu kaiju de nuestros gigantes elementales y eliminar al grupo conflictivo con catástrofes naturales como un tsunami. Las animaciones de los humanos son bastante entretenidas y con mucha personalidad, tanto cuando encuentran cosas nuevas como cuando interactúan entre ellos o son atacados por una catástrofe.
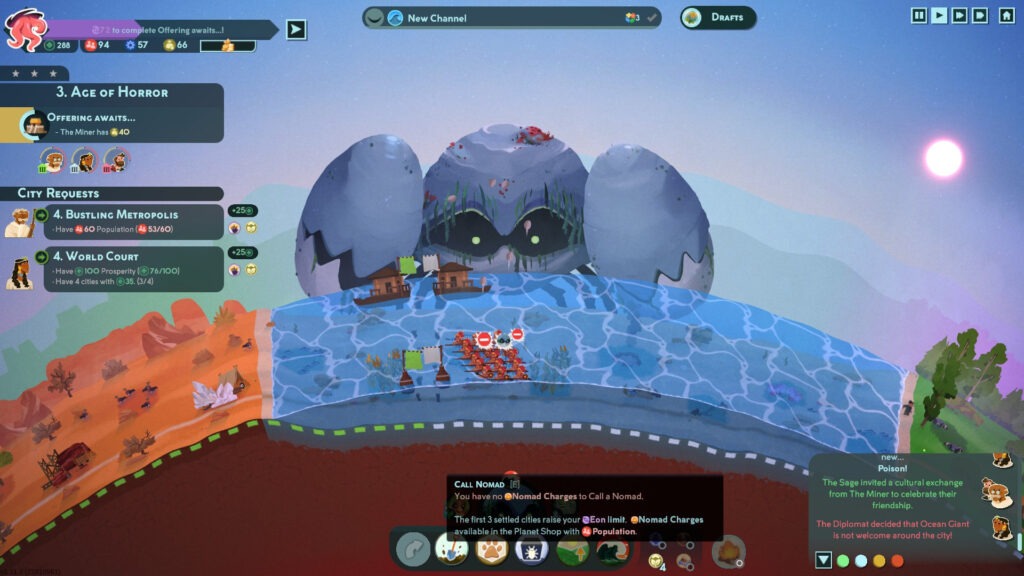
Reus 2 - A veces los humanos deciden ponerse conflictivos
Reus 2 - Pero podemos interferir en sus planes con los poderes de los gigantes elementales
Si los humanos se enojan, pueden llegar a querer atacar a nuestros gigantes elementales. Podemos aceptarlo o enseñarles una lección, enviando un terremoto, fuego y otros desastres naturales para mostrarles quién manda. Es muy divertido, y cuando iniciamos un ataque la música cambia a algo bien dramático que esperaríamos de una película de ataque de monstruos gigantes.
El arte del juego está muy bueno, la fauna, flora, y minerales se van haciendo reconocibles y con el tiempo vamos a tener que ir aprendiendo más por cada bioma. Los diseños de los gigantes elementales me gustan, representativos de sus biomas y con apariencia de amables y bonachones. Pero donde nos hagan enojar, los podemos hacer comportar como verdaderos monstruos. Me gusta el estilo tranquilo y relajante del juego, por eso cuando los humanos se ponen violentos respondo con todo el poder elemental de los gigantes 
Recientemente se lanzó el tercer DLC para Reus 2 Praderas. Este incluye:
- Nuevo bioma - Estepa, con un aspecto renovado para el Gigante Jangwa y más de 65 nuevas especies de flora y fauna, como el Bisonte y el Perro de las Praderas.
- Nueva mecánica de incendios, donde el estrés del suelo provoca fuegos que generan efectos en cadena, fortaleciendo y regenerando la naturaleza.
- 4 nuevos líderes: Agricultor, Cultista, Arquitecto y Astronauta, cada uno con estilos de juego únicos.
- 3 nuevas eras: Ciudad Fabulosa, Planeta Celestial y Sueño Biocinético, que abren caminos inéditos para la evolución de la humanidad.
La verdad que estos DLC están bastante completos, le agregan un montón de diversidad y son una buena razón para volver a jugarlo.
El Perro de las Praderas es una de las especies del nuevo bioma Estepa incluido en el DLC Praderas
El juego está disponible en Steam, Nintendo Switch y XBox. En Steam está publicado en Windows, pero lo he estado jugando con Proton 10.0-4 en Garuda Linux y funciona perfecto. También está verificado como compatible con Steam Deck. Es un juego de estrategia muy entretenido al que vale la pena volver para jugar "un planeta más".
El post Reus 2 + DLC Praderas - Steam fue publicado originalmente en Picando Código.Navegapolis
BurlaBurlando
febrero 18, 2026 06:51
Para desaprender cómo se hacen (o hacían) las cosas sin IA, esta Navidad estuve jugando a hacer un programa con un asistente.
La idea era construir algo para retar y evaluar: la capacidad de un asistente al trazar y ejecutar planes de codificación, y la capacidad de comprensión léxica y razonamiento lógico de los LLM’s.
He empleado:
– Codificación: Antigravity con Gemini 3 Pro (High)
– Imágenes: ChatGPT 5.2 Thinking
– Retos de razonamiento y léxico que muestra el juego: Gemini 3 Pro (High)
– Asesoramiento para levantar y configurar un servidor AWS lihthsail: ChatGPT 5.2 Thinking
Me ha parecido increíble (y creo que también inquietante) el «aumento» que esto puede dar a alguien que tenga conocimientos básicos (fui programador -no muy bueno- y hace más de 20 años).
Por si además puede ser útil dejo el resultado en burlaburlando.com (el dominio de un proyecto que nunca hice).
Toda la codificación, preguntas y retos lógicos que genera, los ha desarrollado una IA.
La entrada BurlaBurlando se publicó primero en Navegápolis.
Picando Código
List Category Posts v0.94.0 - Año nuevo, "vulnerabilidad crítica de seguridad" nueva
febrero 16, 2026 09:24
![]() Desde octubre la cosa estaba bastante tranquila en el frente List Category Posts, el plugin que desarrollé para WordPress. El año pasado empezaron los reportes de seguridad de supuestas vulnerabilidades del plugin. Inicialmente demoré demasiado en corregirlo, por lo que Wordfence alarmó a todos los usuarios de List Category Posts con una advertencia de que sufría de una vulnerabilidad.
Desde octubre la cosa estaba bastante tranquila en el frente List Category Posts, el plugin que desarrollé para WordPress. El año pasado empezaron los reportes de seguridad de supuestas vulnerabilidades del plugin. Inicialmente demoré demasiado en corregirlo, por lo que Wordfence alarmó a todos los usuarios de List Category Posts con una advertencia de que sufría de una vulnerabilidad.
La advertencia debió ser bastante alarmista, pero el peligro era prácticamente inexistente. Las vulnerabilidades no podían ser explotadas, a menos que el sistema ya estuviera comprometido y un atacante tuviera acceso al panel de administración. Documenté estas ocurrencias en varias ocasiones. En capítulos anteriores de Picando Código:
- Arreglada vulnerabilidad CVE-2025-47636 en List Category Posts
- Publicado List Category Posts v0.92.0 con mejoras en "seguridad"
- Nada que ver en las audaces aventuras de desarrollar un proyecto de código abierto popular
- List Category Posts v0.93.0 donde se corrigen "problemas" y re-aprendo PHP
En fin, acá estamos de nuevo con otra ocasión donde se reportaron nuevos problemas. Mientras corregía uno, me llegó otro correo de Wordfence con otro similar, y eventualmente el mismo reportado por Patchstack. Está bueno esto de entender cómo funciona el proceso en el que se informa responsablemente de un CVE con su ID, puntaje y demás. Este último tiene el id CVE ID: CVE-2026-0553.
A partir de hoy está disponible List Category Posts v0.94.0, que corrige dos "vulnerabilidades" que realmente no lo son tanto. Ya que estaba decidí actualizar otra parte del código, a ver si resuelve un problema reportado en el foro que no pude reproducir en mi ambiente de desarrollo.
Escribí el código medio rápido porque lo quería sacar cuanto antes. Pero por suerte está Klemens que ha aportado un montón de código y se acuerda de cosas que yo no. Siempre lo menciono en los Pull Requests porque respeto mucho su opinión y generalmente sabe más que yo de PHP y WordPress. Probé el código en local y confirmé que las vulnerabilidades reportadas habían sido resueltas sin romper nada en general y que los tests pasan. Pero Klemens me recordó que ya había resuelto esos mismos problemas anteriormente. Así que gracias a su revisión del código, lo mantuve más consistente con lo que había hecho en ocasiones anteriores.
El plugin tiene un puntaje muy bueno en el rating de WordPress.org, 4.7 de 5. La mayoría de los usuarios están bastante contentos, y eso está bueno. Se me dio por ir a mirar si había algo nuevo, y de hecho encontré una reseña escrita hace algo más de un mes que me dejó muy contento.
Titulada "Fantastic", la reseña dice: Este es un plugin absolutamente asombroso porque se puede usar de tantas formas diferentes desde por ejemplo crear una página de navegación que lista las páginas categorizadas con "Navegación", a crear "Páginas relacionadas", etc. Hasta puede usarse con etiquetas, no sólo categorías. Y más. Es la idea, por más que empezó como una herramienta que uso para mi blog, poder compartirla y hacerle la vida más fácil a otra gente con el mismo código.
Wordfence generalmente me enviaba el reporte por email. Pero recientemente publicaron un portal para gestionar vulnerabilidades. Asumí que por ahí venía la mano de tanto reporte. Por su lado tienen un interés comercial. Por el de nuestro plugin, todo el trabajo es voluntario y por el simple hecho de compartirlo con la comunidad. Mi respuesta inicial fue que no quería crearme una cuenta más en internet, si era posible que me avisaran por correo de todas formas. Después de un tiempo me convencieron. Pero intenté hacerme una cuenta, y no funcionaba el token que me habían mandado, así que me dí por vencido.
Me volvieron a convencer más recientemente y creé una cuenta. Ahora sólo tenía que agregar mis plugins de WordPress y verificar que eran míos. Por alguna razón, el sistema detecta que el código está en GitHub, y me pide que suba un archivo a la raíz del dominio para verificar que soy el dueño del código... Sí, me pide que suba un archivo de texto a la raíz de github.com. Estamos en 2026 y estas cosas salen a producción. Una empresa de expertos en seguridad. Les escribí al respecto, pero creo que decidieron ignorarlo y no me han dicho nada. Pero bueno, seguiré pidiendo que me manden los reportes por correo electrónico como se debe...

List Category Posts es un plugin para WordPress, es software libre publicado bajo la GPLv2. El código fuente está disponible en Codeberg, en GitHub y en WordPress.org (SVN). Se puede descargar desde el sitio de plugins de WordPress.
El post List Category Posts v0.94.0 - Año nuevo, "vulnerabilidad crítica de seguridad" nueva fue publicado originalmente en Picando Código.Picando Código
Números
febrero 05, 2026 10:30
Últimamente he ido identificando ciertos números "hito" tanto en este blog como en lo personal. Así que usé esos números como excusa para escribir.

Las ruinas de lo que queda de una comunidad rural de Drippan en Glen Finglas, Escocia.
En enero escribí mucho
En Enero de 2026, publiqué 16 entradas en el blog. Mirando el dropdown de archivos del blog, desde 2021 no escribía tantos posts en el mismo mes. En esa época estaba en pleno encierro post pandemia. Mentalmente me encontraba en un lugar bastante particular. Escribir en el blog era un escape y una forma de intentar conectar con el mundo exterior, aunque en su momento no tuve mucho éxito (estaba todo el mundo en un lugar particular en su cabeza).
Recientemente la motivación ha sido distinta. He estado escribiendo porque me gusta, porque tengo ganas y porque siento que tengo cosas para escribir. También he escrito cosas con las que estoy bastante conforme. Eso me motiva más a escribir y al estar en ese ritmo, me resulta más fácil y me surgen más ideas. Se ve que estoy en una etapa creativa, hay que seguir alimentándola. ¡Ojalá pudiera dedicarle más tiempo a proyectos creativos! Dijo toda persona con trabajo siempre.
El mes de febrero empezó bastante ocupadocon cosas fuera de la computadora así que recién estoy volviendo a escribir de nuevo. Tengo muchas cosas que quiero publicar, así que este fin de semana seguramente use un tiempo para ponerme al día.
Otra cosa que he notado en el blog es que han aumentado los comentarios, tanto en las entradas como a través de Mastodon. Muchas gracias a la gente que se toma el tiempo de dejar un comentario, es parte muy valiosa de un blog.
También veo los frutos de empezar a leer más blogs en español y conectar con más gente y directorios. Empiezo a sentir una ilusión de comunidad virtual como la que existía hace muchos años entorno a los blogs. Era cuestión de ponerle un poco de esfuerzo de nuevo. Por ejemplo leyendo un blog y reconociendo autores de otros blogs en los comentarios "¡A ese también lo leo!".
Números del blog
Al escribir esto tengo 317 entradas de borrador en el blog. Este año espero poder bajar ese número a algo más razonable. Muchas veces empecé a escribir algo y me quedé sin energía a mitad de camino, dejando un post sin terminar delegado al limbo de los borradores. Pero también estoy intentando no ser tan exigente con lo que publico. A veces unas pocas palabras sobre algo es mejor que nada, y me motiva a volver a escribir otra cosa más adelante. La constancia genera constancia.
Voy a tener que darme por vencido con un montón de cosas, eliminar el borrador y seguir adelante. Pero ya rescaté otro montón de entradas. Seguramente rescate alguna cosa más, y publique entradas que se puedan sentir "nostálgicas" llamémoslas porque las empecé hace años. Espero mantener esta constancia porque lo disfruto y me sirve de referencia para el futuro. Tengo borradores de 2008, algunos son sólo el título y no tengo ni idea qué quería escribir. Como experimento de repente hago una entrada a partir de esos borradores con tan poco contenido que ni idea por dónde venían. A ver qué sale.
Esta es la entrada 1784 en el blog. No es un número que se vea muy redondo, 1 + 7 es 8, 7 es primo y 8 y 4 son múltiplos de 2 y 2^2 y 2^3 respectivamente. Pero lo interesante es que la cosa se acerca a las 2.000 entradas. Veremos si llegamos. Estaría bueno celebrarlo de alguna manera, podría hacer sorteos del estilo que he hecho antes en el blog o algo más, pero me gustaría algo más interactivo. Si hice bien las cuentas, manteniendo un ritmo promedio de 9 entradas por mes en el blog, en 2 años estamos festejando esas 2.000 entradas.
Aproveché la movida de los números para escribir un poco de SQL y ver cuántos comentarios de usuarios hay (excluyendo pingbacks y trackbacks):
El resultado son 6862 comentarios de personas (incluyéndome). Casi 4 comentarios por entrada, ¡nada mal!
Cumpleaños de Picando Código
En junio de 2025, este blog cumplió 18 años en línea. Un montón de años para cualquier tipo de proyecto o página web. Es como una extensión de mi persona a esta altura. Me ha ido acompañando a lo largo de mi carrera, por etapas de más y menos constancia.
Bah, en verdad no es tanto una extensión de mi persona, sino una extensión del personaje de turno que esté a cargo en mi cabeza al momento de escribir cada entrada en el blog. De los delirion, opininones y sentimientos que elijo exponer públicamente a la internet a través de este medio. De distintos objetivos y motivaciones para escribir a lo largo de los años. Pero sí una expresión creativa que viene de mí.
Renové el dominio y hosting por un par de años más, así que el blog va a cumplir sus 20 años en línea en 2027. Si llega en línea al 2030, voy a haber vivido más años con Picando Código que años sin Picando Código. Quién sabe qué pasará en 2030, y si la vida en el planeta se sostiene hasta entonces con lo que viene pasando. Pero dejo acá una referencia en el tiempo, así tengo algo de qué escribir en 2030 y puedo hacer un flashback a esta entrada. Si leen esto y siguen acá entonces, pueden decir "¡yo me acuerdo de ese flashback!" en 2030.
Cumpleaños de Fernandito
En julio de 2025, cumplí 40 años, otro montón de años más. Qué buen año 1985, salió Super Mario Bros. y Volver al Futuro. No tengo mucho para escribir sobre el tema. Un mensaje que le daría a gente que va entrando a sus 30 es una advertencia que nunca me dieron. Los adultos nunca me avisaron que el pelo que perdemos en el cuero cabelludo crece en las orejas. Sí, a esta edad aparte de andar recortándose los pelos de la nariz, hay que afeitarse las orejas. Esta es parte importante de la sabiduría que he acumulado en mis primeras 4 décadas, por más a las órdenes, brebaje mediante.
Estamos en 2026, ¿se dan cuenta? 2025 no me sonaba tan especial porque es un múltiplo de 5 y siempre se sienten como puntos de referencia o fechas artificiales (cerebro funciona raro). Capaz mi mente está condicionada con los 5 porque me resulta fácil calcular mi edad en base a años que terminan en 5 (aparte de que sea la mitad del sistema decimal que usamos para todo). Pero 2026 se siente como un año bien en los dos miles.
Habiendo vivido el cambio de milenio, suena a año en pleno futuro. Estamos en el futuro y se siente como que de repente nos tendríamos que haber quedado con lo que teníamos al principio del milenio y no mucho más. Antes me preguntaba si tendríamos autos voladores y jetpacks. Ahora anhelo la abolición de los millonarios y que no se extinga la vida en el planeta a causa del capitalismo. Y dicen que uno se vuelve más conservador con la edad.
Creo que ya deliré suficiente con esto. Mejor la dejo acá...
Picando Código
Reemplazando Mozilla Firefox
enero 29, 2026 09:00
Como comenté en un post anterior, estoy dejando de usar Firefox. Una condición de este cambio es no usar un navegador web basado en el motor de Google Chrome. Google Chrome es el Internet Explorer 6 de éstos tiempos, así que quedan descartados un montón de navegadores web populares.
Hace tiempo que Mozilla parece estar buscando perder usuarios de Firefox de gusto. Pero el problema más notorio recientemente ha sido su compromiso con usar lo que los tecnofascistas millonarios cocainómanos de Sillicon Valley nos quieren vender a prepo con el término marketinero de "Inteligencia Artificial" ("IA" a partir de ahora, para acortar). Esto ha generado mucho rechazo (con razón) de una gran parte de sus usuarios. No quiero entrar en mi postura del tema de IA porque me entra a subir la presión y no es el tema de este post. Pero el consenso general parece ser que Mozilla debería preocuparse por hacer a Firefox el mejor navegador web posible, y no meterle IA a prepo.
Por suerte todavía hay muchas opciones, a continuación comento qué he ido haciendo. Potencialmente escriba más posts en el futuro sobre este tema. Definitivamente estoy prestando más atención recientemente al desarrollo de alternativas a Firefox, así que lo que vaya encontrando interesante lo compartiré por acá.
Descartado por ahora: GNU IceCat

GNU IceCat
En el pasado usé bastante IceCat, pero en algún momento dejaron de funcionar los repositorios o algo de eso. Tengo una instalación vieja en el directorio ~/bin de mi sistema, pero aparentemente no tiene la habilidad de actualizarse sólo a versiones más nuevas. Hace muchos años hasta escribí un post Usando IceCat como reemplazo de Mozilla Firefox: Perfiles de usuario. Esto de llevarme el perfil a otro navegador me puede resultar útil, pero ya veremos más adelante...
La página web de GNU IceCat dice: El proyecto actualmente no distribuye binarios, pero el gestor de paquetes GNU Guix puede ser usado para instalar IceCat en sistemas GNU/Linux. También hay instrucciones para hacer tu propia versión de IceCat con scripts del repositorio git de GNUzilla y el código fuente de Firefox. Todo bien, en algún momento de repente me interesaría aprender y probar Guix. Y compilar el código puede llegar a ser divertido. Pero en este momento estoy intentando reemplazar Firefox y no tengo tiempo.
Aparentemente sólo hay binarios de versiones no oficiales, y no encontré un PPA confiable como para agregar a APT. Hay uno con versiones arcaicas de IceCat que creo que lo encontré buscando en este mismo blog. Pero en fin, queda descartado porque no me inspira demasiada confianza su futuro. De repente con la cantidad de usuarios que nos vamos yendo de Firefox es un buen momento para volcar más recursos en el mantenimiento de IceCat, pero parece que ahora no es prioridad. Si remonta un poco la actividad, lo volveré a considerar.
Debian Iceweasel
Debian Iceweasel
En mi búsqueda pensé si no sería un bueno momento también para que vuevla Iceweasel. Entre Debian Etch y Debian Jesse la versión de Firefox empaquetada por Debian llevaba el nombre de Iceweasel. Esto era para no infringir con la marca registrada de Mozilla. El Firefox que venía en Debian no era "oficial", le aplicaban sus propios parches y cambios al navegador. Mozilla consideraba estos cambios fuera de su política, así que el paquete no se podía considerar "Firefox".
Más adelante Debian fue autorizado a volver a la marca de "Firefox" y Iceweasel desapareció. Esto es lo que recuerdo, pero seguramente falten muchos detalles. Sé que hay hasta una entrada en Wikipedia sobre la pelea por la marca registrada de Firefox entre Mozilla y Debian para leer más del tema.
Debian igual hace algunos cambios a la configuración por defecto de Firefox en su versión .deb. En esta wiki hay más detalles, aunque está muy desactualizada. Ahí mismo comentan: "Firefox hace una serie de conexiones automatizadas a servidores de Mozilla (y de otros) sin pedir la aprobación explícita del usuario". Así que están pendientes de la telemetría y los problemas de privacidad de Firefox.
Es posible que en algún momento consideren que el desarrollo de Firefox diverge tanto de lo que es aceptable en Debian, que decidan volver a hacer su propia versión. Ya hay un bug reportado de 2025 donde cuestionan que los nuevos términos de uso de Firefox sean compatibles con Debian. En la conversación está Sylvestre Ledru, desarrollador de Debian desde hace muchos años y director en Mozilla, involucrado en su momento con el tema Iceweasel/Firefox. También Mike Hommey, uno de los desarrolladores más prolíficos de Mozilla en número de commits, empleado de Mozilla y quien estuvo manteniendo Firefox/Iceweasel en Debian muchos años.
Sería interesante, veremos qué pasa. Tanto hablar de Debian me dieron ganas de volver a Debian...
Waterfox y LibreWolf
De la poca investigación y lo que he fui leyendo, éstos dos parecen ser los forks más populares de Firefox éstos días. Instalé ambos, pero a lo que empecé a usar Waterfox y todo funcionó bien, me quedé con eso. Tengo instalado LibreWolf, pero sinceramente no lo he usado mucho.
Waterfox

Waterfox
Encontré una guía de instalación que usaba el repositorio APT de OpenSUSE (Hola OpenSUSE, ¡tanto tiempo!). Pero poco después me enteré que el repositorio dejó de ser mantenido, así que no recibiría más actualizaciones. Así que descargué el binario para Linux desde la página web oficial y desinstalé el deb. Por suerte todo siguió igual, la versión instalada a mano levantó el mismo perfil que la anterior.
{kind=link}
También lo instalé en mi teléfono y lo sincronicé con la versión del escritorio. Todo funcionó bien. Pensé en hacer lo que comentaba en la sección de IceCat, de importar mi perfil de Firefox y mantener la experiencia. Pero aproveché la oportunidad para empezar de cero y tener una experiencia limpia.
Me importé todos los Favoritos (o Bookmarks) de Firefox. Instalé sólo un par de extensiones, ya ni recuerdo cuáles venían instaladas y cuáles no. Pero esenciales son uBlockOrigin y una que descubrí gracias a FireDragon: Dark Reader. Agrega la opción de tener "modo oscuro" para cualquier página, muy conveniente para no quedar encandilados en páginas con fondo blanco. Ya no puedo usar el escritorio de WordPress sin Dark Reader...
Desde que Mozilla paró el desarrollo de Lockwise, migré mis contraseñas a Bitwarden. Instalé la extensión de Bitwarden para mis passwords, y listo. En principio tenía Firefox Nightly y Waterfox funcionando a la vez. Entonces si necesitaba algo de Firefox me lo traía a mano. Pero hace bastante ya que no necesito abrir Firefox.
Personalicé un poco la interfaz de usuario a mi gusto. Creo que por defecto traía la barra de estado, algo medio old school que ocupa un poco de espacio en la parte inferior de la pantalla. De ahí saqué el botón para sacar capturas de pantalla, una herramienta que uso seguido, y lo moví a la barra superior junto al menú de favoritos y extensiones.
Creé varios contenedores, un invento excelente de Mozilla cuando todavía eran buenos. Me creé contenedores específicos para servicios, por ejemplo todo lo que sea de Google corre en su contenedor. Con la opción de abrir siempre esas páginas en el contenedor, no tenemos ni que pensar. Aproveché la mudanza para usarlos mucho más y tener perfiles de navegación separados dentro del mismo navegador.
Una característica genial de Waterfox es que te permite abrir pestañas privadas en la misma ventana de navegación que estás usando para las pestañas comunes. Hasta donde sé, Firefox no tenía esta característica, sólo abrir enlaces en ventanas nuevas privadas.
Waterfox publicó en su blog una respuesta directa al uso de IA por Mozilla: No AI* Here - A Response to Mozilla's Next Chapter. La parte que concierne a inclusión de AI en el navegador se resume en "Waterfox no incluirá LLMs. Punto y aparte. Al menos y definitivamente no en su forma actual ni en el futuro previsible".
Después de esos primeros días donde personalicé y dejé el navegador a gusto, todo viene funcionando bien, como esperaba. No noto muchas diferencias con Firefox, de repente anda mejor, pero puede ser porque en Firefox tengo cientos de pestañas abiertas, algunas de hace muchos años... Y el perfil de usuario lo vengo arrastrando hace años en distintas versiones de Firefox y de Sistemas Operativos. Uh, otra cosa que agregaron en la última versión de Waterfox que está muy buena es "des-cargar" pestañas (des cargar onda de sacarlas de la memoria) desde el menú contextual. Hacemos clic derecho en una pestaña y nos aparece la opción.
El paso que me queda es un día sentarme a recorrer todas esas pestañas que tengo abiertas en Firefox, exportar a favoritos las cosas que quiere leer o volver a visitar, y cerrar el resto. Así finalmente voy a poder desinstalar Firefox y olvidarme del tema. Pero como navegador principal por ahora vengo usando Waterfox y estoy conforme.
LibreWolf

LibreWolf
Como mencioné, no llegué a usar mucho LibreWolf. Pero no veo por qué no sería una buena opción para reemplazar Firefox.
Es un fork popular y sus metas son la privacidad, seguridad y libertad de los usuarios. Está diseñado para mejorar la protección contra técnicas de rastreo y fingerprinting, e incluye mejoras de seguridad a través de opciones por defecto y parches. También elimina toda la telemetría, colección de información y molestias, y deshabilita características anti-libertad como DRM. Esto último podría ser un problema a la hora de usar servicios de streaming imagino, pero seguro hay alguna vuelta para solucionarlo.
Incluye uBlockOrigin por defecto, esa extensión esencial. Hace años que no tengo ni idea cómo se ven los anuncios en la web, y cada vez que veo uno en la pantalla de otra persona me agobio. El gestor de contraseñas viene deshabilitado, recomiendan usar un gestor mejor y entre las opciones sugieren Bitwarden.
Su repositorio de código está alojado en Codeberg. No tienen versión de Android, pero recomiendan IronFox como alternativa, un proyecto que voy a revisar y tener en cuenta.
FireDragon (Garuda Linux)

FireDragon
Además de KDE Neon como distribución principal, también vengo usando Garuda Linux. En ese sistema no tuve que hacer nada porque el navegador web por defecto es FireDragon:
FireDragon es un navegador basado en el excelente navegador Floorp (también llamado el Vivaldi de los Firefox). Fue personalizado para tener una estética similar al sistema así como muchas preferencias opinionadas por defecto. Como este navegador era originalmente un fork de Librewolf, estamos tratando de integrar sus mejores parches y cambios en la base nueva.
Floorps es otra opción a tener en cuenta, pero en lo personal no me interesó. Tienen una postura definida, distinta a Mozilla, en cuanto al uso de IA: No respaldamos completamente ni rechazamos explícitamente IA. Respetamos las decisiones de los usuarios que quieren usar IA y de los que no. Cualquier característica de IA agregada a Floorp será en base de optar por usarlo. Van a estar desactivados a menos que sean habilitados por el usuario.
A tener en cuenta, en esa misma página hacen un comentario bastante ridículo: Para mantener un paso de desarrollo que soporte a usuarios en todo el mundo, es esencial la asistencia de herramientas de IA (como GitHub Copilot). Si van a usar esas porquerías, háganse cargo, no salgan con ese bolazo de que es "esencial".
Además de las preferencias de Floorps, FireDragon tiene un montón de personalizaciones. Cuenta con Firefox accounts pero usa un servidor de sincronización a medida. Un detalle visual es que cuando un botón está deshabilitado (por ejemplo los botones de navegación adelante y atrás si no hay nada adelante o atrás), desaparecen en vez de quedar en color gris. Si bien es el navegador de Garuda Linux, se puede instalar en otros sistemas. Está disponible en AUR, NixOS, Flatpak, AppImage y binarios para Linux y los otros sistemas privativos.
FireDragon, el navegador web de Garuda Linux (ArchLinux) corriendo en KDE Neon (Ubuntu)
Tor Browser

Tor Browser
Tor Browser es el navegador web del proyecto Tor. Si no conoces el proyecto Tor y el navegador, este es un buen lugar para empezar. La misión de Tor es:
Promover los derechos humanos y las libertades mediante la creación y despliegue de tecnologías de anonimato y privacidad libres y de código abierto, el apoyo a su disponibilidad y utilización sin restricciones y el fomento de su comprensión científica y popular.
Tengo el navegador instalado, pero no lo uso mucho. No tengo mucha necesidad, creo. Cuando quiero un poco de privacidad extra me conecto a la VPN y uso el siguiente navegador. Se siente como que cargar las redes de Tor con mi uso de repente le puede quitar ancho de banda a gente que realmente lo necesita. Pero es una buena opción si necesitamos privacidad y no contamos con VPN.
Mullvad Browser

Mullvad Browser
Mullvad es el navegador web creado por Tor Project y distribuido por Mullvad. Mullvad es mi proveedor actual de VPN (¿ya vieron la gema Ruby que hice para eso?).
Usar una VPN no es suficiente para mantener el anonimato en línea. Las empresas usan todo tipo de estrategia para identificar y rastrear nuestra actividad. El navegador web puede ser usado para identificarnos por la información que comparte con los sitios web. Algunos navegadores son peores que otros en ese aspecto.
El navegador de Mullvad es lo mismo que Tor Browser pero sin la red Tor. Aprovecha todas las características orientadas a la privacidad y se integra con Mullvad VPN. Usa la estrategia "esconderse entre la multitud", con configuraciones y preferencias que hacen que todos los usuarios del navegador se vean parecidos para estas empresas que intentan identificarnos.
Este es el navegador que uso con la VPN para la mayor privacidad.
Pale Moon

Pale Moon
Escribí sobre Pale Moon en el blog hace poco. Recomiendo leer ese post para ver más. Además de lo ya dicho, también hicieron pública su postura respecto a incluir IA en el navegador: No, Pale Moon no va a integrar IA en sí mismo de ninguna manera, forma o modo. Coincido con su desarrollador que esto de meter IA hasta en la sopa es uno de los errores más grandes que viene haciendo actualmente el sector IT en su conjunto.
Pale Moon es de los navegadores que venía usando en paralelo con Firefox desde hace un buen tiempo. Me parece bueno eso de tener distintos navegadores para distintos perfiles de navegación. Particularmente cuando cada vez es más lo que hacemos a través de la web. También espero que ayude con el tema de la identificación, que los anunciantes y otras empresas nefastas intentando compilar información y rastrear actividades en línea les cueste más si no usamos siempre el mismo navegador web.
Pale Moon es una buena opción. No probé usarlo como reemplazo total a Firefox, pero imagino que no tendría demasiado problema. En el peor de los casos si algo no funciona, es una buena oportunidad para replantearse si realmente uno necesita visitar la página. Y como respaldo, siempre podemos abrir la página en otro de los navegadores de esta lista.
SeaMonkey

SeaMonkey
Le tengo muchísimo cariño al navegador web SeaMonkey. Lo vengo usando hace muchísimos años, potencialmente desde sus inicios. En su momento usaba la Mozilla Application Suite, el paquete de aplicaciones para Internet con un navegador, cliente de correo, lector de noticias, desarrollador de páginas web y cliente para IRC. SeaMonkey continúa el desarrollo de ese paquete con actualizaciones de alta calidad.
El proyecto está en constante desarrollo, la versión más actual se publicó el 31 de diciembre de 2025. Tuvo algunos problemas con las actualizaciones automáticas por una migración que están realizando de Azure a OSUOSL, una organización sin fines de lucro trabajando en el avance de las tecnologías de código abierto. El blog de SeaMonkey se actualiza relativamente seguido. Es un buen recurso para ver cómo avanza el proyecto.
Al igual que Pale Moon, es un navegador que uso en paralelo con otros desde hace mucho tiempo. Me divierte probar navegadores web distintos y acostumbrarme a la experiencia de usuario y particularidades de los que me gustan. Tanto SeaMonkey como Pale Moon son forks de código de Mozilla, pero de bastante tiempo atrás. Son como continuaciones alternativas de lo que podría haber sido Firefox en un universo paralelo, muy buenas opciones ambos.
Integrando esos ejecutables
En varios casos como Pale Moon, SeaMonkey, Mullvad y Waterfox, estoy usando un ejecutable descargado de la página de lanzamientos de cada proyecto. Éstos en general se actualizan sólos, buscan versiones nuevas al ejecutarse y actualizan el código automáticamente. Como comenté, al momento de escribir esto SeaMonkey tiene un problema con las actualizaciones. Pero parece que ya está medio resuelto (yo terminé haciendo la actualización a mano). En otros casos, deberíamos suscribirnos a los feeds de lanzamiento para estar al tanto de versiones nuevas (por ejemplo el feed de FireDragon) y hacer las actualizaciones a mano.
Un tema adicional a la hora de usar estos ejecutables es integrarlos con el sistema. Que nuestro lanzador de aplicaciones los encuentre para poder ejecutarlos desde ahí. Para eso escribí un post hace un tiempo - Agregar aplicaciones al lanzador de GNOME Shell, KDE o Unity y vengo usando lo mismo. Podemos personalizar el ícono, o generalmente lo encontramos en los directorios de cada navegador:
- SeaMonkey: chrome/icons/default/
- Pale Moon, Waterfox, FireDragon y demás forks de Firefox: browser/chrome/icons/default/
Otros proyectos
Otros proyectos a tener en cuenta a futuro son Ladybird y Servo.
Servo es un motor de navegador web desarrollado inicialmente en Mozilla. Pero Mozilla echó a todo el equipo de Servo en 2020, y el proyecto fue adoptado por la Linux Foundation de Europa. Siguió su desarrollo gracias a voluntarios hasta 2023 que hubo una inversión que permitió que el proyecto se reactivara. En 2024 se anunció un "reboot" de Servo y desde octubre de 2025 se vienen publicando versiones de desarrollo mensualmente.
Es un motor, una vez que sea estable podría incluirse en navegadores web para tener una experiencia completa y moderna.

Estaremos atentos a su carrera con gran interés
Conclusión
Esto es a rasgos generales cómo vengo reemplazando Firefox. Los navegadores que más vengo usando son Waterfox y Pale Moon. Pero cada tanto también SeaMonkey y Mullvad, y en el caso de Garuda uso FireDragon. Pero ese sistema lo uso más que nada para jugar, así que no hago uso intensivo del navegador web ahí.
Es una lástima que después de tantos años de confiar en Mozilla y usar Firefox estemos acá. Pero insisto en que para mí, la gente a cargo de Mozilla está haciendo fuerza para perder más usuarios de Firefox. Eso va a ser un desastre "interesante" de mirar desde lejos.
{kind=link}
Seguramente vuelva a escribir más sobre el tema. Por ejemplo no hablé mucho de qué vengo usando en mi teléfono aparte de Waterfox. Pero ya me extendí bastante por esta vez. Espero que si están considerando reemplazar Firefox, mis comentarios ayuden en algo, y con suerte conozcan y prueben un navegador nuevo.
El post Reemplazando Mozilla Firefox fue publicado originalmente en Picando Código.Navegapolis
Spec-Driven Development
diciembre 24, 2025 08:53
El contexto: los problemas del vibe coding
Para entender Spec-Driven Developmen (SDD) o, hablando en nuestro idioma: desarrollo guiado por especificaciones, es bueno empezar conociendo el problema que intenta solucionar.
En febrero de 2025, Andrej Karpathy (cofundador de OpenAI y exdirector de IA en Tesla) acuñó el término vibe coding en un tweet que se hizo viral(1)
«Hay un nuevo tipo de programación que llamo ‘vibe coding’, donde te dejas llevar completamente por las vibraciones, abrazas los exponenciales, y olvidas que el código siquiera existe. […] Acepto todo siempre, ya no leo los diffs. Cuando recibo mensajes de error, simplemente los copio y pego sin comentarios, y normalmente eso lo arregla.»
Para proyectos de fin de semana o prototipos rápidos, dejarse llevar por la IA puede funcionar, pero tiene limitaciones: código aparentemente correcto, pero con bugs sutiles, arquitecturas inconsistentes, vulnerabilidades de seguridad, y la incomodidad de no conocer la lógica que implementa el código generado.
Los datos son reveladores: según Y Combinator, el 25% de las startups de su cohorte de invierno 2025 tenían bases de código generadas en un 95% por IA(2). Es impresionante, pero: ¿quién entiende y mantiene ese código?
Qué es Spec Driven Development
Spec Driven Development es, en esencia, un enfoque en el que la especificación precede y guía al código. No es un framework ni una metodología prescriptiva como scrum. Es una filosofía de trabajo que propone:
- Escribir primero una especificación clara de lo que se desea construir: objetivos, reglas de negocio, criterios de aceptación, restricciones técnicas.
- Usar esa especificación como fuente tanto para humanos como para agentes de IA.
- Generar código a partir de la spec, no de prompts improvisados.
Como lo resume GitHub en su documentación de Spec Kit: «En este nuevo mundo, mantener software significa evolucionar especificaciones. […] El código es el enfoque de última milla.»(3)
Los tres niveles de SDD
Birgitta Böckeler, de Thoughtworks, propone una taxonomía útil para entender las diferentes implementaciones(4):
- Spec-first: Escribes la spec antes de codificar, la usas para la tarea en curso, y luego la descartas. Es el nivel más básico.
- Spec-anchored: La spec se mantiene después de completar la tarea y se usa para evolución y mantenimiento del feature.
- Spec-as-source: La spec es el artefacto principal. Solo editas la spec, nunca tocas el código directamente. El código se regenera desde la especificación.
La mayoría de herramientas actuales operan en el nivel spec-first, algunas aspiran a spec-anchored, y solo unas pocas experimentan con spec-as-source (como Tessl Framework).
La relación con IA: el catalizador del resurgimiento
Aunque la idea de «especificar antes de codificar» está en el origen de la ingeniería de software, SDD ha resurgido ahora por una razón específica: los LLMs necesitan contexto estructurado para generar código coherente.
Piénsalo así: cuando le das a un agente de código un prompt vago como «hazme un login», está adivinando arquitectura, patrones, validaciones y flujos de error. Cuando le das una especificación detallada que define exactamente qué debe pasar, el código resultante tiene muchas más probabilidades de hacer lo que necesitas.
La spec funciona como un «super-prompt» persistente y versionable. Como describe el equipo de Kiro (AWS): «Una especificación es una especie de super-prompt (versionado, legible por humanos).»(5)
Herramientas del ecosistema
El ecosistema de herramientas SDD está creciendo rápidamente(6):
- GitHub Spec Kit: Toolkit open source que proporciona un flujo estructurado: Constitution → Specify → Plan → Tasks → Implement. Funciona con Copilot, Claude Code y otros.
- Kiro (AWS): IDE basado en VS Code con flujo integrado de Requirements → Design → Tasks.
- Tessl Framework: Explora el nivel spec-as-source con mapeo 1:1 entre specs y archivos de código.
- BMAD Method: Usa agentes virtuales (Analyst, Product Manager, Architect) para generar PRDs y specs de arquitectura.
SDD, TDD y BDD: primos cercanos, no competidores
Si trabajas con metodologías ágiles, probablemente te preguntarás cómo encaja SDD con prácticas que ya conoces. La buena noticia: no son excluyentes, son complementarias(7).
- TDD (Test Driven Development): Tests primero. Escribes un test que falla, luego el código para pasarlo. Excelente para calidad a nivel de unidad, pero no captura el intent de producto completo.
- BDD (Behavior Driven Development): Comportamiento primero. Escenarios en formato Given-When-Then que describen cómo se comporta el sistema. Fuerte para alineación con stakeholders, pero deja decisiones técnicas abiertas.
- SDD (Spec Driven Development): Especificación primero. Define el qué y el por qué, añade un plan técnico, y descompone en tareas. La spec es el ancla que mantiene a todos (humanos y agentes) alineados.
En la práctica, puedes usar SDD para definir el feature completo, TDD para cada tarea individual, y BDD para validaciones end-to-end. Como dice Beam.ai: «SDD te dice qué y por qué. BDD verifica comportamiento en todo el sistema. TDD asegura corrección a nivel de código. Estas prácticas funcionan bien juntas.»
La tensión con Agile (y cómo resolverla)
La pregunta incómoda surge porque el Manifiesto Ágil dice «software funcionando sobre documentación extensiva», y esto contradice SDD ese principio al pedir especificaciones detalladas.
La respuesta corta es que depende de cómo lo implementes; y la respuesta larga es que SDD no propone documentación extensiva estilo waterfall. Propone especificaciones vivas, ejecutables y versionadas que evolucionan con el código. Como GitHub lo describe: «Spec-Driven Development no se trata de escribir documentos de requisitos exhaustivos que nadie lee. Tampoco se trata de planificación waterfall.» (3)
En la práctica, SDD funciona bien a nivel de feature o sprint. No estás especificando todo el producto de antemano; estás especificando la siguiente funcionalidad con suficiente detalle para que un agente de IA pueda implementarla correctamente.
Consideraciones críticas y limitaciones
Pero SDD puede no ser una bala de plata. Estos son los puntos de crítica más relevantes en la comunidad profesional:
El problema humano
Como señala Daniel Sogl en DEV Community: «El problema principal no es la IA, es el factor humano. SDD requiere que los desarrolladores especifiquen sus intenciones con precisión. […] Después de más de 10 años en desarrollo de software, rara vez he experimentado proyectos donde los requisitos estuvieran completamente formulados antes de la implementación.»(8)
Escribir buenas specs es difícil. Requiere claridad de pensamiento, conocimiento del dominio, y la disciplina de pensar antes de actuar.
Overhead vs. beneficio
Birgitta Böckeler de Thoughtworks probó varias herramientas SDD y encontró que para tareas pequeñas, el proceso era desproporcionado: «Cuando pedí a Kiro que arreglara un pequeño bug, el documento de requisitos lo convirtió en 4 ‘user stories’ con 16 criterios de aceptación […] Era como usar un mazo para romper una nuez.»(4)
SDD tiene más sentido para features medianos a grandes donde la inversión upfront se amortiza en menos correcciones posteriores.
Falsa sensación de control
Las ventanas de contexto son más grandes, pero eso no significa que la IA siga todas las instrucciones. Böckeler observó: «Frecuentemente vi al agente no seguir todas las instrucciones. […] También vi al agente excederse porque seguía instrucciones demasiado ávidamente.»(4)
Las specs ayudan, pero no eliminan el no-determinismo de los LLMs. Todavía necesitas revisar y validar.
¿Revisar markdown o código?
Algunas herramientas generan cantidades masivas de archivos markdown. Como comenta Böckeler: «Honestamente, preferiría revisar código que todos estos archivos markdown. […] Eran repetitivos y tediosos de revisar.»(4)
Una buena herramienta SDD debería proporcionar una experiencia de revisión de specs genuinamente mejor que revisar código, no peor.
Entonces, ¿merece la pena?
Como con cualquier práctica emergente, la respuesta honesta es: depende.
SDD probablemente te beneficie si:
- Trabajas regularmente con agentes de código IA
- Tus proyectos tienen complejidad media-alta
- Valoras la trazabilidad y la documentación viva
- Tu equipo puede invertir tiempo en aprender un nuevo flujo de trabajo
Probablemente no lo necesites si:
- Solo haces prototipos rápidos o proyectos personales
- Tu trabajo consiste principalmente en fixes pequeños y mantenimiento
- Prefieres un control directo y granular sobre cada línea de código
Si decides probarlo, el consejo del equipo de AI Native Dev es pragmático: «Empieza con un feature. No especifiques toda tu aplicación. Elige una funcionalidad bien entendida y escribe una spec detallada. Ve cómo rinde tu agente de IA.»(9)
Como resume el equipo de AI Native Dev: «Estamos todos descubriendo esto juntos, y los patrones que emerjan vendrán de experiencias compartidas entre cientos de equipos.»(9)
Fuentes citadas
[1]: Andrej Karpathy en X (Twitter), 2 de febrero de 2025: x.com/karpathy/status/1886192184808149383
[2]: «Vibe coding» – Wikipedia. Datos de Y Combinator: es.wikipedia.org/wiki/Vibe_coding
[3]: GitHub Blog – Spec-driven development with AI: github.blog/ai-and-ml/generative-ai/spec-driven-development-with-ai
[4]: Birgitta Böckeler, Thoughtworks – Understanding Spec-Driven-Development: Kiro, spec-kit, and Tessl: martinfowler.com/articles/exploring-gen-ai/sdd-3-tools.html
[5]: Kiro – The future of AI spec-driven software development: kiro.dev/blog/kiro-and-the-future-of-software-development
[6]: Microsoft for Developers – Diving Into Spec-Driven Development With GitHub Spec Kit: developer.microsoft.com/blog/spec-driven-development-spec-kit
[7]: Beam.ai – Spec Driven Development: The Future of Building with AI: beam.ai/agentic-insights/spec-driven-development
[8]: Daniel Sogl – Spec Driven Development: A initial review, DEV Community: dev.to/danielsogl/spec-driven-development-sdd-a-initial-review-2llp
[9]: AI Native Dev – Spec-Driven Development: 10 things you need to know about specs: ainativedev.io/news/spec-driven-development-10-things-you-need-to-know-about-specs
La entrada Spec-Driven Development se publicó primero en Navegápolis.
Koalite
Sobre velocidad y coste de desarrollo
diciembre 19, 2025 09:19
Al desarrollar software, y más cuando se trata de un producto maduro, es habitual que surga la sensación de que «antes sacábamos cambios rápido y ahora todo va más lento» y, por tanto, se proponga «contratar más gente para volver a ir rápido».
Desde fuera puede parecer que el equipo simplemente se ha vuelto menos eficiente. Desde dentro, normalmente lo que está pasando es bastante más mecánico y predecible:
- A medida que el software crece, su coste mínimo de mantenimiento y evolución sube.
- A medida que crece el equipo, la capacidad productiva media por persona decrece.
Esto, que puede parecer algo exclusivo del mundo del desarrollo, es algo que pasa en más ámbitos, como el nivel de vida de una persona o algo tan básico como organizar una habitación.
La complejidad tiene un coste
Cuando un software es pequeño, tiene pocas piezas, pocas reglas, pocas integraciones y pocos casos especiales. Cambiar algo es parecido a mover un mueble en una habitación vacía: lo haces rápido y rara vez rompes nada.
Con el tiempo el producto crece: más funcionalidades, más pantallas, más configuraciones, más clientes con necesidades distintas, más integraciones externas, más datos históricos, más restricciones.
El sistema se convierte en un conjunto de piezas que encajan entre sí. Y ese encaje tiene un precio. Ya no estamos moviendo un mueble en una habitación vacía; estamos intentando cambiar de sitio un armario ropero en una habitación llena de muebles.
En la práctica, esto se nota en tres cosas:
- Entender lo que hay cuesta más: antes podías leer una parte del código y ya. Ahora entender un cambio requiere saber cómo afecta a otras piezas.
- Hacer un cambio correctamente cuesta más : hay más validaciones, más tests, más revisiones, más compatibilidad hacia atrás, más escenarios que no puedes romper.
- Los errores se vuelven más probables y más caros: no porque la gente programe peor, sino porque hay más interacciones posibles. Además, cuando aparece un bug, cuesta más investigar su origen.
Si lo llevamos al nivel de vida de una persona, pasa algo parecido.
Si vives con tus padres, llevas una vida sencilla y no necesitas muchas cosas, tu coste fijo es bajo y puedes llegar a fin de mes sin problemas con poco dinero. A medida que tu vida se va complicado, y te compras una casa, tienes un hijo o te compras un coche, tu coste fijo va aumentando y cada vez necesitas más dinero para llegar fin de mes.
Esto es lo que pasa en software: cuando es sencillo, un cambio puede costar un par de días, pero cuando va ganando en complejidad, ese mismo cambio puede requerir un par de semanas para poder tener en cuenta todas las interacciones con el resto del sistema.
Es una consecuencia natural de tener más cosas funcionando y más cosas que no puedes romper.
Escalar el equipo ayuda, pero con rendimientos decrecientes
Cuando el coste sube la reacción típica es: «contratemos más gente». Es algo que ayuda y tiene un impacto positivo. Pero hasta cierto punto.
Hay quien piensa que si 2 personas producen 10, aumentando a 4 producirán 20. O producirán 10, pero en la mitad de tiempo. Por desgracia, no es tan sencillo, y, en general, al aumentar el número de personas, la productividad media por persona irá disminuyendo.
¿Por qué disminuye la productividad por persona al aumentar el número de personas?
Hay dos motivos principales.
La falta de contexto. Una persona nueva puede ser muy buena, pero empieza con desventaja:
- No conoce el producto en detalle.
- No conoce los “porqués” históricos (decisiones pasadas, limitaciones, clientes clave).
- No conoce los riesgos escondidos (lo que no se debe tocar sin cuidado).
Al principio, esa persona necesita tiempo de formación y, además, tiempo de otras personas para ayudarle: explicaciones, revisiones, acompañamiento, correcciones. Con el tiempo se convierte en productiva, pero no es inmediato.
El coste de coordinación interno del equipo.
Cuando un equipo es pequeño pasa mucho tiempo junto, hay pocas tareas abiertas en paralelo, y todo el mundo está al tanto de todo. Al ir creciendo esto cambia: aparecen más reuniones, más tareas en paralelo que dependen unas de otras, más necesidad de alinear criterios (qué se hace, cómo, etc.).
Aunque se pueda trabajar en más frentes en paralelo, cada iniciativa individual suele avanzar más lento porque necesita más coordinación y aumenta el coste de comunicación.
Si volvemos a compararlo con el nivel de vida, es similar a lo que ocurre con los impuestos. Supongamos que cuando tenías una vida sencilla, con 12.000€ brutos al año conseguías 1.000€ netos al mes y te podías apañar. Podrías pensar que cuando la complejidad de tu vida aumenta te basta con aumenta linealmente tus ingresos, pero no es así: si duplicas tu ingresos y ganas 24.000€ brutos al año, mensualmente sólo recibes 1.600€. Los siguientes 12.000€ no han multiplicado por dos tu capacidad de asumir costes, sino sólo por 1.6.
Algo parecido ocurre al incorporar personas a un equipo. Duplicar el tamaño del equipo no multiplica su capacidad de producción por 2, sino por un factor menor.
Conclusiones
Es necesario entender que cuando aumenta la complejidad del software los cambios cuestan más, no porque el equipo sea menos competetente, sino porque, sencillamente, los cambios son más difíciles y costosos de hacer.
Contratar más gente ayuda, pero es necesario asumir un coste inicial de formación y un coste de coordinación creciente, por lo que no cabe esperar un crecimiento de la productividad lineal con respecto al número de personas.
Para recuperar la velocidad hay que tener en cuenta otros factores, como reducir la complejidad simplificando el software, eliminando casos especiales, automatizando procesos y, sobre todo, teniendo unas prioridades claras para evitar que unas tareas acaben compitiendo con otras.
Si entendemos que el software tiene un coste fijo creciente y que los equipos tienen rendimientos decrecientes al crecer, el foco de la conversación cambia. Ya no es «¿por qué somos más lentos?», sino «¿qué complejidad estamos acumulado? ¿la necesitamos? ¿cómo la vamos a gestionar?».
Una sinfonía en C#
¿Cómo conectar Kakfa-UI con Event Hubs de Azure?
diciembre 02, 2025 12:00
“Introducción”
Si usamos Eventhubs de Azure como broker Kafka, y queremos usar Kafka-UI para monitorizar los topics, tenemos que tener en cuenta algunas cosas para que funcione. Hablando siempre de autenticación utilizando SASL_SSL con mecanismo PLAIN. (Esto no funciona para Managed Identity).
En principio sabemos que podemos definir un connection string SAS para conectarnos a Event Hubs, pero Kafka-UI no soporta directamente este formato, por lo que tenemos que hacer algunos ajustes.
KAfka en generar no soporta este formado, sino que hay que hacer un mapeo de los valores del connection string a las propiedades que Kafka espera, más específicamente en el usuario y password, además de protocolo de comunicación.
Configuración de Client Kafka
Para conectar un cliente Kafka a Event Hubs, tenemos que mapear los valores del connection string a las propiedades de usuario y password. Pero primero hay que configurar:
- Protocol: SASL_SSL
- Mechanism: PLAIN
Y luego en las propiedades de autenticación:
- Username: $ConnectionString
- Password: Endpoint=sb://.servicebus.windows.net/;SharedAccessKeyName=;SharedAccessKey=;EntityPath=
El EntityPath es opcional, y solo si queremos conectarnos a un Event Hub específico. Si no se especifica, se puede acceder a todos los Event Hubs dentro del namespace.
Básicamente el username es el literal $ConnectionString (con el signo $) y el password es el connection string completo.
Conectar Kafka-UI
En el caso de Kafka-UI tenemos un truco adicional, que sería agregar al user name un $ adicional al inicio, quedando así:
- Username: $$ConnectionString
- Password: Endpoint=sb://.servicebus.windows.net/;SharedAccess
Esto en la propiedad KAFKA_CLUSTERS_0_PROPERTIES_SASL_JAAS_CONFIG (reemplazar el 0 por el índice del cluster que estemos configurando).
En el caso de un docker-compose.yml, quedaría algo así:
version: '2'
services:
kafka-ui:
image: provectuslabs/kafka-ui:latest
ports:
- 9999:8080
environment:
- KAFKA_CLUSTERS_0_NAME=azure
- KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS=xxxx.servicebus.windows.net:9093
- KAFKA_CLUSTERS_0_PROPERTIES_SECURITY_PROTOCOL=SASL_SSL
- KAFKA_CLUSTERS_0_PROPERTIES_SASL_MECHANISM=PLAIN
- KAFKA_CLUSTERS_0_PROPERTIES_SASL_JAAS_CONFIG=org.apache.kafka.common.security.plain.PlainLoginModule required username='$$ConnectionString' password='Endpoint=sb://<NAMESPACE>.servicebus.windows.net/;SharedAccessKeyName=<KEY_NAME>;SharedAccessKey=<KEY_VALUE>';
El connection string tiene que tener scope del namespace (lo que sería el broker de Kafka).
Especial cuidado al doble $ en el username y al ; final
Nos leemos.
Arragonán
Viviendo en el péndulo. Hasta la vista Genially
octubre 13, 2025 12:00
Tras casi 4 años, esta fue mi última semana en Genially. Una decisión que me costó mucho tomar tanto por motivos personales, con un ambiente de compañerismo en la compañía que creo que no es habitual en otros lugares que tienen cierta escala y haber construido lazos con un buen puñado de personas; como por motivos profesionales, con unos cuantos desafíos que se venían a corto y medio plazo en los que sé que hubiera disfrutado y aprendido.
En este tiempo, mi rol en la empresa se fue transformando poco a poco casi sin darnos cuenta, primero influenciando solo a nivel de tecnología y terminando haciéndolo a nivel de producto, negocio y operaciones. Hubo algo que fue una constante: vivir en el péndulo entre individual/team contributor y el management.
Incorporación
Entré casi por casualidad. Conocí a Chema, CTO de Genially, unos años antes en una Pamplona Crafters y mantuvimos el contacto vía redes sociales (cuando tuiter aún molaba). Tiempo después, hablamos por otro tema y me propuso explorar si tenía sentido incorporarme. La compañía venía de crecer mucho y vieron que podía asumir un rol que resultase complementario.
Justo era un momento en el que empezaba a sentir que necesitaba un cambio profesional, pero quería estar seguro de mi siguiente paso. Así que tras haber hecho el proceso de selección, nos tomamos un par de meses y tuvimos varias conversaciones hasta que finalmente me incorporé a la compañía.
Plataforma y organización
Entré con un rol de Platform Lead, por lo que mi responsabilidad iba a ser ayudar a los equipos de producto a que pudieran enfocarse en tener impacto, tratando de mejorar la experiencia de desarrollo y la efectividad de los equipos. Como bonus, también iba a echar una mano en cuestiones más organizativas.
Aunque este era un rol de liderazgo, no había un equipo dedicado, de modo que iba a tener que influir, colaborar con distintos equipos y empujar algunas iniciativas por mi cuenta.
Sobre el trabajo de plataforma
Una vez hecho el onboarding, empezar a tener algunas iniciativas ya lanzadas y conociendo más la compañía, traté de aterrizar una serie de metas:
Las iniciativas y actividades de plataforma deben facilitar la Developer Experience y ayudar a los equipos en distintos aspectos:
- Reducir su carga cognitiva, que se enfoquen en complejidad intrínseca y no en la extrínseca, potenciando la germana (generando aprendizaje, construyendo esquemas o automatizando su uso)
- Habilitar actitudes data-informed en la toma de decisiones
- Aportar la mayor autonomía y empoderamiento posibles
- Tratar de ser lo más eficientes en cuestiones de costes económicos
- Dar fiabilidad, que las herramientas apenas fallen
Metas que traté de tener en cuenta, definiendo e implantando prácticas, procesos y herramientas, automatizando tareas, creando documentación… Y darles seguimiento unas veces de manera cuantitativa y otras de forma cualitativa.
Algunas de las iniciativas más relevantes fueron estas:
- Actuar como puente entre el equipo de infraestructura y los equipos de producto para acelerar la implantación del stack de observabilidad de Grafana (Loki, Mimir, Tempo).
- Formalizar la redacción de postmortems blameless tras incidencias que afecten al servicio junto a CTO y VP de ingeniería, para fomentar el aprendizaje sistémico.
- Apoyar al equipo de Design System con distintas actividades.
- Ayudar en la introducción de Snowplow + Amplitude para la instrumentación de producto colaborando con el equipo de data y los primeros equipos de producto involucrados.
- Introducir el uso de Turborepo en el monorepo para simplificar el proceso de build.
- …
A nivel organizativo
Durante esos primeros meses se estaba planteando una reorganización del área de desarrollo de producto bastante importante. Básicamente era pasar de una estructura de squads que se organizaba de forma recurrente a una basada en líneas de trabajo que tuvieran continuidad en el tiempo.
Esto fue algo en el que me involucraron aún sin tener mucho contexto junto al resto de managers de tech y producto, en parte venía bien tener a alguien con mirada limpia aunque en ocasiones pudiera pecar de ingenuo, para cuestionar supuestos y detectar disonancias.
En aquel entonces me resultó muy útil que alguna de la gente involucrada en la reorganización estuviera hablando en términos de Team Topologies, porque nos ayudaba a tener un lenguaje común. Eso lo terminamos enfrentando con un ejercicio de Context Mapping (en un par de eventos charlé sobre ello), donde representamos buena parte del funcionamiento de la compañía para ver el encaje de equipos respecto a la situación actual.
Este ejercicio sirvió para completar la foto real a la que íbamos, e incluso permitió detectar potenciales problemas de bounded contexts en los que había muchas manos y algunas en las que había muy pocas. Así que cuando con el paso del tiempo surgieron algunos problemas relacionados, no nos pilló tan por sorpresa.
Además, institucionalizamos el dar seguimiento a lo que surgía de las retros de los equipos, ya que se estableció como práctica que se documentase por escrito al menos lo más destacado de ellas y las acciones que surgieran. Esta práctica se mantiene a día de hoy, y resulta muy útil a la capa de management como complemento a los 1:1s para detectar fricciones y puntos de mejora.
Mucho de esto y algunas cosas más, las compartí en la charla Desarrollo de producto en una Scale-Up precisamente en la Pamplona Crafters 2024.

Volviendo a hacer producto (interno)
Tras un año, mi foco cambió a ser algo más todoterreno. Por un lado, ya tenía bastante controladas las dinámicas en el área de desarrollo de producto y a nivel de plataforma había aún puntos de mejora en los que iba trabajando, pero estábamos ya más en una fase de mejora continua y constante, además el equipo de infraestructura seguía introduciendo grandes mejoras. Mientras tanto, en otras áreas de la compañía se identificaban problemas mayores con los que creíamos que podía aportar más.
Ventas
Uno que terminó surgiendo fue en el equipo de ventas, al que había que buscarle solución de forma prioritaria, ya que ninguna de las líneas de trabajo a priori tenía foco en ese tema. Teníamos un proceso interno ineficiente y propenso a errores que terminaban sufriendo clientes High Touch de gran tamaño: muchos emails y llamadas de coordinación, uso de spreadsheets de gestión, tiempos de espera por parte de clientes y account managers, etc.
Para solventar el problema se decidió montar un squad específico moviendo a algunos perfiles técnicos desde algunas líneas de trabajo, y como no queríamos sacar de foco a product managers terminé involucrado en la fase de discovery para abordarlo.
Así que tocó entender los problemas que el equipo de ventas se estaba encontrando y, junto a compañeras de customer experience, entrevistarnos con clientes y gente del área de ventas. A partir de ahí, documentar el impacto que estaba teniendo, definir un primer alcance del MVP usando un user story map y preparar un kick-off para tener tanto al squad, stakeholders y el resto de la compañía alineados.
El squad trabajó en una herramienta que diera mayor autonomía a esos clientes de gran tamaño, permitiendo a account managers mantener el control y darles seguimiento. Y en mi caso, aunque no tiré ni una línea de código y que luego me quedase acompañando al squad de lejos casi como un stakeholder más, me lo pasé como un enano volviendo a participar en hacer producto en fases iniciales.
Creativo
Tiempo más tarde, nos encontrarnos otro problema importante en el área de creativo. Uno de los valores que ofrece Genially a las personas usuarias son las plantillas diseñadas por este equipo. Nos encontramos con un problema de atasco en la publicación de nuevas plantillas y cambios en las existentes que antaño no ocurría, el producto había evolucionado de un modo en el que terminó afectando en la operativa diaria de este equipo.
Esto es porque una vez diseñadas, existía un cuello de botella en el proceso de publicación tanto en el producto como en la web pública. Esta ineficiencia en el Go to Market provocaba tardar más tiempo en recuperar la inversión, era propenso a errores y frustraba a las personas de ese equipo.
Al final era un problema para el que la perspectiva Lean encajaba como anillo al dedo: Identificar el valor, mapear el flujo de trabajo, mantener un flujo continuo, aplicar sistema pull y buscar la mejora continua. Para lo cual se decidió crear de nuevo un squad que se enfocara en esta área.
Una vez analizado y mapeado el journey principal que queríamos resolver, habiendo identificado los distintos hand-offs y limitaciones de las herramientas, planteamos crear un nuevo backoffice diseñado para habilitar mayor autonomía y que simplificase su proceso. De ese modo podríamos sustituir de forma incremental el backoffice legacy, un CMS y un par de spreadsheets de gestión.
Para acelerar el proceso de publicación introdujimos: soporte i18n, gestión de estados, uso de IA generativa, mejoras en las validaciones… Además de crear un servicio que pudiera consumirse desde el producto y la web, cosa que evitaba el uso de herramientas externas y, a nivel técnico, simplificaba la infraestructura y la mantenibilidad futura.
Una vez eliminado ese cuello de botella, que con la combinación del trabajo del squad con el equipo creativo pasó de un retraso de 4 meses a estar al día, nos centramos en mover y mejorar el resto de procesos que se soportaban aún en el legacy en esta nueva herramienta, y en el camino colaborar con uno de los equipos de producto para introducir algunas mejoras conjuntamente.
Operaciones y tech
Aproximadamente el último año en Genially mi rol terminó pivotando de manera oficial a trabajar con foco en las operaciones internas de la compañía. Esto significaba estar en un punto medio entre tecnología, producto, negocio, organización y su potencial impacto en la operativa diaria de cualquier área de la compañía. Esto implicaba mucha amplitud y normalmente menor profundidad, mucha comunicación, intentar promover iniciativas que tuvieran sentido o frenar las que aparentemente necesitasen reflexionarse más, identificar posibles problemas entre áreas de forma prematura, moverme todavía más habitualmente entre diferentes grados de abstracción, etc.
Siempre con una perspectiva de desarrollo de producto, durante ese tiempo tuve oportunidad de trabajar de nuevo y esta vez mucho más involucrado con el área de ventas y desarrollo de negocio; además de empezar a hacerlo también con las de financiero, personas, soporte y comunidad.
Trabajando con más áreas
Con el área de ventas empezamos a trabajar en hacer crecer el MVP que arrancamos antaño, soportando nuevas casuísticas primero y luego acercando e integrando esta herramienta con el CRM que se usa en la compañía. En mi caso había estado involucrado en el día a día de la línea de trabajo que lo evoluciona, con un rol de facilitador y ocasionalmente de desatascador.
Junto a las áreas de financiero y personas hicimos pequeñas iniciativas coordinadas con líneas de trabajo de producto, aunque algunas más ambiciosas se quedaron en el tintero porque el coste de llevarlas a cabo las hacían inviables al menos en el medio plazo.
Con soporte empecé a trabajar muy de cerca, ya que había una tormenta perfecta de cambios en el producto, iteraciones de negocio, atasco en los tiempos de respuesta y degradación de la experiencia de cliente.
Lanzamos varias acciones para solventar la situación: mejorar flujos en el chatbot, rehacer la integración con la herramienta de soporte para enriquecer la información de clientes y mejorar la gestión de colas, introducir automatizaciones, contratar e integrar a un proveedor para pasar a tener un chat basado en agentes de IA que escalase sólo casos complejos, etc. Una vez recuperada una situación de normalidad pudimos entrar en un modo de mejora continua en soporte, y poder dedicar más tiempo a iniciativas relacionadas con comunidad.
Y en medio de todo esto apoyar en ajustes organizacionales, tanto a nivel de desarrollo de producto como en el resto de áreas; y en iniciativas transversales, por ejemplo y para sorpresa de nadie, últimamente con foco en un par relacionadas con IA generativa.

Conclusión
Aunque al inicio costó un poco ver cómo gestionar ese tipo de rol pendular en el que a veces era difícil manejar la cantidad de cambios de foco y de niveles de abstracción, se me dio siempre confianza y autonomía. Finalmente me sentí muy cómodo con ese tipo de responsabilidades.
Me permitió poder influir a nivel organizativo como un manager primero a nivel de área y luego tratar de hacerlo a nivel de compañía, aunque sin las responsabilidades de gestión de personas. Y de vez en cuando poder ejecutar trabajo directamente por ejemplo programando, documentando o investigando de forma autónoma o colaborando con más personas en equipo.
Tras tener la oportunidad de trabajar con tanta gente diferente y variedad de áreas en el contexto de una scale-up, cierro esta etapa en Genially habiendo crecido mucho profesionalmente y con un montón de aprendizajes: técnicos, organizativos, de personas, de negocio… y siendo un fan de la marca y la compañía.
Y ahora ¿qué?
Toca arrancar una aventura nueva que no esperaba, uno de esos trenes que sientes que son una gran oportunidad que tienes que tomar, pero eso lo cuento un poco más adelante en otro post.
Meta-Info
¿Que es?
Planeta Código es un agregador de weblogs sobre programación y desarrollo en castellano. Si eres lector te permite seguirlos de modo cómodo en esta misma página o mediante el fichero de subscripción.
Puedes utilizar las siguientes imagenes para enlazar PlanetaCodigo:
![]()
![]()
Si tienes un weblog de programación y quieres ser añadido aquí, envíame un email solicitándolo.
Idea: Juanjo Navarro
Diseño: Albin
Fuentes
- Arragonán
- Bitácora de Javier Gutiérrez Chamorro (Guti)
- Blog Bitix
- Blog de Diego Gómez Deck
- Blog de Federico Varela
- Blog de Julio César Pérez Arques
- Bloggingg
- Buayacorp
- Coding Potions
- DGG
- Es intuitivo...
- Fixed Buffer
- Header Files
- IOKode
- Infectogroovalistic
- Ingenieria de Software / Software Engineering / Project Management / Business Process Management
- Juanjo Navarro
- Koalite
- La luna ilumina por igual a culpables e inocentes
- Made In Flex
- Mal Código
- Mascando Bits
- Metodologías ágiles. De lo racional a la inspiración.
- Navegapolis
- PHP Senior
- Pensamientos ágiles
- Picando Código
- Poesía Binaria
- Preparando SCJP
- Pwned's blog - Desarrollo de Tecnologia
- Rubí Sobre Rieles
- Spejman's Blog
- Thefull
- USANDO C# (C SHARP)
- Una sinfonía en C#
- Variable not found
- Yet Another Programming Weblog
- design-nation.blog/es
- info.xailer.com
- proyectos Ágiles
- psé
- vnsjava