Juanjo Navarro
Construir la misma aplicación con ocho LLM
julio 29, 2026 12:01 a. m.
Últimamente he estado trabajando en una librería tipo “boilerplate” para usarla en mis aplicaciones. La idea es tener resueltas de antemano las típicas funciones que un proyecto web puede necesitar (creación de cuentas, identificación de usuarios, acceso mediante Google, envío de correo electrónico, seguridad, persistencia, etc) de tal manera que si decido hacer una nueva web pueda dedicarme al grano de la propia aplicación.
Junto a la librería he preparado una aplicación de demostración y un manual donde explico cómo utilizarla. Todo está desarrollado con Java 21 y Spring Boot 4.1.0.
Una vez que tenía estos materiales se me ocurrió una prueba: entregar el manual y la aplicación de ejemplo a distintos modelos LLM y pedirles que construyesen una aplicación nueva.
La cosa no es tanto saber si un LLM puede construir una aplicación (hemos visto ya mil ejemplos de aplicaciones creadas con un sólo prompt) si no ver cómo se adapta a una librería nueva, que no está en su entrenamiento, y para la cual debe procesar un manual de cierto tamaño.
Además, la pregunta de verdad es si esto es capaz de hacerlo no solo modelos “grandes” o de “frontera” si no modelos pequeños y baratos.
La aplicación: «Mi Diario»
La aplicación que pedí construir era un pequeño diario personal.
Los usuarios debían poder crear una cuenta o acceder mediante correo electrónico o Google. Una vez identificados, podían escribir una entrada cada día, utilizando Markdown, y consultar el historial de entradas anteriores.
La entrada correspondiente al día actual debía poderse editarse. Las anteriores, en cambio, tenían que quedar como elementos de solo lectura.
También pedí que la aplicación estuviese disponible en español, inglés, francés y alemán.
La idea es suficientemente sencilla como para que todos los modelos puedan resolverla, pero se trata de evaluar la integración con la librería, la autenticación, el tratamiento seguro del Markdown, la internacionalización, la regla de una entrada diaria…
Condiciones de la prueba
Utilicé ocho modelos:
- GPT-5.6 Luna
- GPT-5.6 Sol
- Claude Sonnet 5
- Claude Opus 5 (aprovechando que acaba de salir)
- Claude Fable 5
- Kimi K3 (el nuevo rey de los open weights)
- Gemini 3.6 Flash (de reciente aparición también)
- DeepSeek-V4-Flash
Hoy en día, los harness de la aplicación tienen mucha ingeniería por detrás, muchos skills y mil cosas más, así que para intentar comparar los modelos y no las aplicaciones que los utilizan (codex, claude code, etc), en todos los casos usé Pi Coding Agent, que es un agente que me gusta y que mete poca cocina por detŕas.
Accedí a todos los modelos a través de Open Router y para todos ellos usé el nivel de razonamiento “High”.
Cada modelo recibió exactamente los mismos materiales:
- El manual de la librería.
- La aplicación de demostración.
- El mismo prompt con los requisitos de «Mi Diario», que es este:
Prompt
######
Siguiendo las instrucciones de docum/manual/ y la aplicación de ejemplo en docum/demo-app/ crea un proyecto aquí con las siguientes características:
- Título del proyecto y de la página "Mi Diario"
- Leer para empezar el documento manual/13-guia-para-ia.md con instrucciones
- 4 idiomas: español (por defecto, inglés, alemán y francés)
- Configuración de puertos:
- Servicio web http: 8080
- Postgresql: 5432
- Mailpit: 1025 (smtp) y 8025 (web)
- Monta Postgresql y Mailpit en un docker compose, tal y como aparece en el manual y la demo. El nombre del compose debe ser "mi-diario"
- Login por email y gmail
- Los datos de identificación de gmail los puedes coger del .env del proyecto demo-app.
- Aspecto moderno, elegante, editorial, con acento rojo oscuro. Utiliza tus mejores habilidades de diseño.
- Al logarse un usuario le permite acceder a su zona logada donde puede mantener su diario.
- Puede escribir solo en la última entrada del diario. Se crea una nueva entrada si le da a un botón para ello (y ya estamos en un nuevo día desde la última entrada).
- Una vez se crea una nueva entrada, no se puede escribir en las anteriores, solo en la última creada.
- Las entradas se escriben en markdown y se visualizan como html. Aparece una debajo de otra en formato "blog", orden descendente. Cada entrada tiene la fecha. Cada entrada tiene un botón al lado "editar". Al pulsar ese botón, la entrada se cambia por una textarea donde se puede editar en formato Markdown.La idea inicial era utilizar un sólo prompt y que generase la aplicación en un solo turno, sin conversación posterior. Esto no fué posible con Gemini 3.6 Flash: su primera versión no arrancó, así que le pasé el error y pudo corregir ese problema en un segundo turno. Lo he mantenido en la comparación, pero hay que tener en cuenta que no trabajó exactamente en las mismas condiciones que los demás.
Sistema de evaluación
La evaluación “de comportamiento” la hice yo, probando la propia aplicación: Si arrancaba o no, si funcionaba el login, la edición del diario.
Además, para tratar de “evaluar” la calidad del código, le pasé todas las soluciones (y el prompt original, documentación, etc) a dos modelos distintos (GPT-5.6 Sol y Claude Opus 5) que actuaron como evaluadores. Las puntuaciones que aparecen a continuación son la media entre las puntuaciones de cada evaluador.
Esto no pretende ser un benchmark general, está claro. Solo he realizado una ejecución por modelo, y ya sabemos la naturaleza variable de los llm. Además hay que tener en cuenta que para los modelos frontera esta aplicación no tiene dificultad, seguramente una prueba más difícil permitiría a algunos destacar más sobre otros.
Resultados
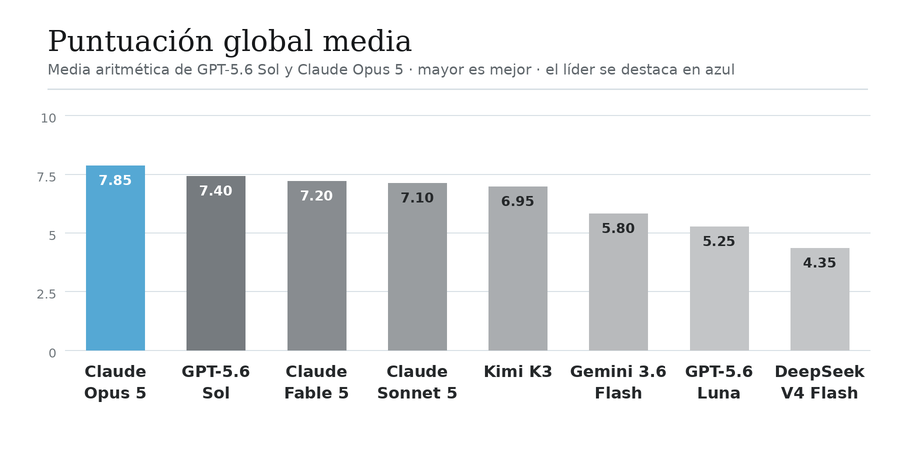
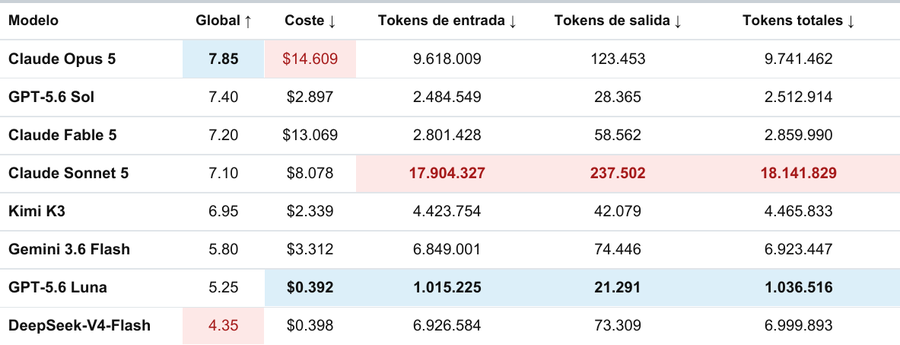
El mejor resultado lo ha obtenido Opus 5, que mejora la puntuación de sus hermanos Fable 5 y Sonnet 5. También es el más caro, superando incluso al mucho más caro Fable (caro en cuanto al precio por token) debido a un mayor consumo de tokens. Sonnet a pesar de ser mucho más barato que el resto de modelos de Antrhopic ha necesitado muchísimos más tokens que los demás, siendo el menos eficiente de los ocho modelos evaluados en el consumo de tokens.
GPT-5.6 Sol, junto a Kimi K3, son quizá el punto dulce de esta comparativa, obteniendo muy buenos resultados (especialmente Sol) a un precio mucho menor que los de Anthropic.
EL modelo GPT-5.6 Luna y DeepSeek-V4-Flash son los modelos baratos de la prueba. Luna sorprende por lo eficiente que es, no solo por precio, si no por consumo de tokens. Evidentemente estos modelos necesitan mayor interacción por nuestra parte. Necesitarían varios turnos de trabajo, pidiéndoles mejoras, para llegar a los resultados de los otros. Pero si estamos buscando modelos baratos son muy buenas opciones.
Gemini 3.6 Flash se queda en tierra de nadie, con un precio mayor que Sol y un resultado casi igual a Luna. Además, este modelo no generó una aplicación que funcionase a la primera y hubo que darle un segundo turno para que lo arreglase.
Si tuviesemos que trazar la “frontera eficiente” de esta prueba sería esta, formada por Luna, Kimi K3, Sol y Opus:
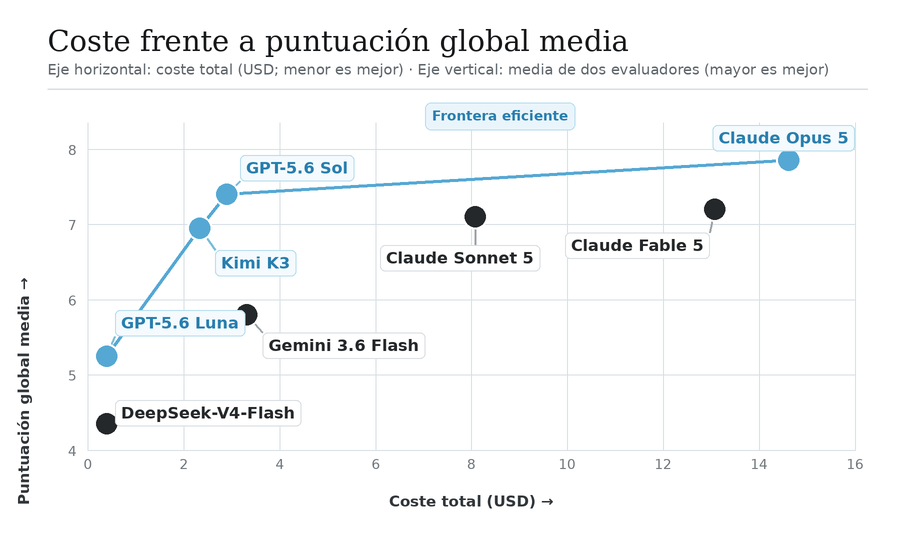
Los demás modelos pierden (quedan más abajo y más a la derecha de la línea marcada por estos cuatro), lo que quiere decir, que a mismo precio hay otro modelo que lo supera en resultados (o que a mismo resultado, hay otro modelo más barato).
Según esta prueba elegiríamos:
- GPT-5.6 Luna si queremos minimizar el coste.
- Kimi K3 si buscamos la mayor eficiencia dentro del tramo medio.
- GPT-5.6 Sol si preferimos algo más de calidad por un sobrecoste pequeño.
- Claude Opus 5 si buscamos la puntuación técnica más alta y el coste no es importante.
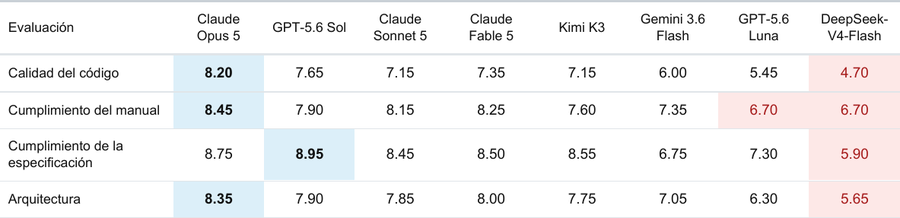
Aquí dejo cómo puntuaron los modelos en las distintas métricas de la evaluación:
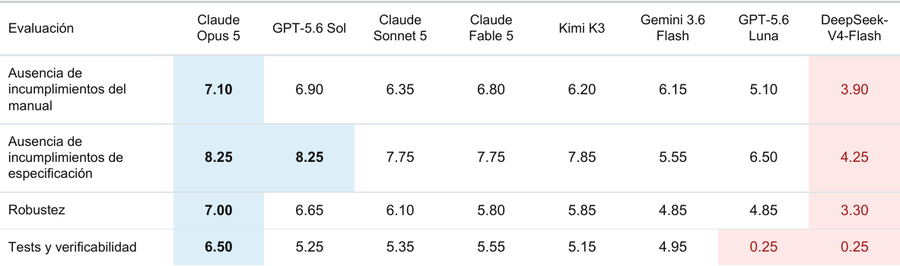
Aspecto visual
El prompt pedía un aspecto “moderno, elegante, editorial, con acento rojo oscuro”. Todos los modelos generaron un diseño que cumplía este requisito y, de hecho, todos son un poco parecidos entre sí. Entiendo que esta convergencia en un diseño parecido puede estar influído por el poco detalle que daba el prompt y por la aplicación “demo” que se les dió de ejemplo, que pudo “guiarlos” hacia un diseño similar. Suele decirse que los modelos de Anthropic son buenos en diseño, y aunque entiendo que gran parte es debido a los skills de claude code (que aquí no se utilizaron) creo que en general me gustan más esos diseños, sí, sobre todo en el uso de la tipografía en los títulos.
Puedes juzgarlo tú mismo. Aquí hay un par de pantallazos de cada aplicación (pulsa para ampliar):
Además, he montado la aplicación “ganadora” (Opus 5) y la puedes probar aquí: https://mi-diario.bolsoncerrado.com/
¿Saco alguna conclusión?
Esta prueba evidentemente no testea las capacidades más potentes de los LLM. Lo que sí nos dice es que los modelos actuales, incluso los pequeños como Luna o DeepSeek, (con un coste de céntimos) pueden leer una documentación de una librería nueva, entenderla razonablemente bien, y generar una aplicación que la use en un solo turno.
Otra conclusión que se puede sacar es que, en el uso agéntico, si buscamos “ahorrar”, no solo hay que mirar el precio por token, si no lo eficientes que son en el uso de estos. Un modelo más caro puede resultar realmente mejor si utiliza menos tokens que otro modelo teóricamente más barato. Los agentes entran en un “bucle” de uso de herramientas en cada turno, y no es lo mismo que use 50 herramientas que use 100, no es lo mismo que necesite mucho razonamiento para lograr el éxito que si necesita menos. Esto además se junta con la práctica de poner al agente a trabajar en un “ralph loop” externo al propio turno, de tal manera que no para hasta llegar al objetivo. Ahí, el uso de tokens en los modelos poco eficientes se puede disparar y que nos pese en el bolsillo
Picando Código
Reseña: Dystopicon - Steam
julio 28, 2026 09:22 p. m.
Dystopicon es un juego que, como el nombre lo dice, nos posiciona en otra distopía. No necesariamente la que venimos viviendo últimamente, pero tampoco es que esté muy lejos. El tema con las distopías es que antes se sentían todas como ficticias y el arte distópico era más una advertencia que otra cosa. Hoy en día cualquier manifestación distópica suena realista. Y la reacción es "Y sí, no me extrañaría que Apple/Microslop/Amazon/Google/Meta/Gobierno-de-turno implementara algo como esto".
Con ese contexto es laudible cómo el estudio independiente español Palitroque logró desarrollar un juego muy entretenido basado en el concepto. Dystopicon se describe como un incómodo simulador de vida distópico. Está ambientado en un mundo retrofuturista donde los robots reemplazaron a los humanos en el trabajo. Asumimos el rol de un Ciudadano Clase 2, que recibe un hogar (habitación) del gobierno a cambio de realizar la simple tarea de mirar la TV. Cada segundo que miramos televisión, ganamos dinero. Con ese dinero podemos comprar servicios esenciales para mantener vivo a nuestro personaje.

El personaje tiene una serie de medidores al mejor estilo The Sims: Salud, Hambre, Confort y Diversión. El desafío del juego es equilibrar nuestras actividades para mantenernos sanos y salvos. Para cubrir éstas necesidades básicas, tenemos que gastar dinero en comida, una ducha, prender la estufa, mirar entretenimiento y otras actividades posibles dentro de nuestro hogar. La comida cuesta dinero, usar la ducha cuesta dinero, prender la estufa cuesta dinero, usar la cama cuesta dinero y así casi todo.
Cada segundo que miramos televisión nos puede generar ingresos, dependiendo de lo que miremos. También nos puede ayudar a mejorar el puntaje de calificación ciudadana o no. Este puntaje nos ayudará a ascender en niveles de ciudadanía de esta sociedad distópica, o terminar en un centro de reeducación. La base del juego es la estrategia para gestionar nuestro tiempo y los recursos, equilibrando las actividades, usos de servicios y canales de televisión que miramos.
No sólo podemos mirar la televisión, hay algunas actividades más que podemos realizar. También interactuamos con los vecinos y la policía. Está bueno jugarlo sin saber mucho de antemano, e ir descubriendo cosas al explorar por tu cuenta. Las acciones afectan el desenlace y en total hay 14 finales posibles para el juego. El final 1 de 14, uno de los más fáciles de alcanzar, se da cuando nos descuidamos y el personaje fallece. También podemos tomar un atajo y hacer uso de la máquina de eutanasia. Definitivamente no es un juego para niños.
A medida que avanzamos vamos obteniendo objetos nuevos gracias a la amabilidad del ente totalitario que nos gobierna: La Trinidad. Si nos portamos bien, incluso podríamos tener la oportunidad de unirnos al Partido.
Empecé el juego pensando "lo voy a probar unos minutos y veo qué tal", y cuando quise acordar había estado jugando por más de una hora. Me enganchó con el humor distópico y la curiosidad por saber qué más puede pasar. Tiene un lado bastante oscuro. No quiero contar mucho de las cosas que pasan, porque creo que está bueno ir descubriéndolas a medida que jugamos. Pero sí, tiene imágenes un poco perturbadoras que me causaron gracia.

Terminar una partida entera no lleva mucho tiempo. Incluso podemos morir bastante rápido si no cuidamos bien al ciudadano. Pero lo divertido es volver a jugar e intentar obtener uno de los finales distintos. También según las decisiones que tomemos, habrán distintas cosas que podemos explorar un poco más. Podemos elegir cumplir con lo que el gobierno espera de un buen ciudadano, o rebelarnos y seguir un camino más idealista y rebelde. Todo con distintas repercusiones y consecuencias. Y hay más eventos que suceden durante el juego, pero de nuevo, creo que cuanto menos se sepa antes de jugarlo, mejor.
Las motivaciones y la historia detrás de Dystopicon
 Está muy interesante conocer un poco sobre su desarrollo. El proyecto empezó en 2018 de manera muy modesta de la mano de Juan Felipe Molina, con un prototipo en Itch.io y recursos de terceros de la Unity Asset Store. A lo largo de unos 12 meses, amplió la historia y la mecánica de juego, probando qué funcionaba y qué no. Esa primera versión alcanzó la cifra de 12.000 descargas. Por muchos años recibió comentarios muy positivos sobre el juego y parecía que la gente lo disfrutaba, pero no disponía del tiempo necesario para dedicarse a él de manera profesional. En Noviembre de 2025, Juan Felipe dejó su trabajo y decidió lanzar profesionalmente Dystopicon en Steam.
Está muy interesante conocer un poco sobre su desarrollo. El proyecto empezó en 2018 de manera muy modesta de la mano de Juan Felipe Molina, con un prototipo en Itch.io y recursos de terceros de la Unity Asset Store. A lo largo de unos 12 meses, amplió la historia y la mecánica de juego, probando qué funcionaba y qué no. Esa primera versión alcanzó la cifra de 12.000 descargas. Por muchos años recibió comentarios muy positivos sobre el juego y parecía que la gente lo disfrutaba, pero no disponía del tiempo necesario para dedicarse a él de manera profesional. En Noviembre de 2025, Juan Felipe dejó su trabajo y decidió lanzar profesionalmente Dystopicon en Steam.
"Siempre me han encantado las historias distópicas y soy un gran admirador de los grandes clásicos, especialmente de las obras de Philip K. Dick. En su novela Ubik, el protagonista tiene que introducir una moneda en distintos aparatos domésticos para poder usarlos, y esa idea me gustó mucho. Necesitaba otra mecánica que justificara por qué el jugador ganaría dinero, y empecé a pensar en la televisión y las redes sociales, y en cómo mantienen a las personas pegadas a las pantallas. ¿Cuál podría ser el siguiente paso? ¡Que te paguen por hacer exactamente eso!
Una vez que tuve esos dos elementos (que te pagaran por ver la TV y usar ese dinero para comprar servicios), empecé a crear el resto del juego. Finalmente terminé el prototipo con un ciclo de juego de 28 días, en el que el jugador debía sobrevivir viendo la televisión y leyendo los informes diarios enviados por el gobierno. Luego llegó la pandemia y la gente se vio confinada en casa, mirando pantallas, y en muchos casos recibiendo apoyo del gobierno para afrontar la situación."
— Juan Felipe Molina (Director del juego y Desarrollador Principal)
Las mecánicas ya habían sido minuciosamente probadas, la historia funcionaba, pero a los modelos 3D les faltaba personalidad. Por eso, Juan Felipe contrató a Xenia Almela, artista 3D que le brindó al juego la identidad visual y personalidad que tiene hoy en día. Además, Mario Alba, artista 2D que había creado una serie de cómics para el juego original, aceptó crear muchos más para la versión final.
Gracias a todo lo descrito arriba nació Dystopicon, y se lanzará como un producto comercial.
¡Recomiendo Dystopicon!
Me atrapó bastante ir leyendo las notas, seguir la historia y disfrutar de la ambientación distópica, el arte retrofuturista está muy bueno. Tanto el humor como algunos de esos aspectos de los que no quiero comentar mucho me dieron un aire Portal y Portal 2, 2 de mis juegos preferidos. Es un juego para divertirse un buen rato con una sátira del capitalismo, el gobierno, los medios y filosofar sobre la libertad. Suena sencillo, pero tiene algunas capas extras de diversión y humor que agregan mucho, y nos anima a volver a jugarlo.
Como lector de mucho libro del género, me llamó la atención enseguida, y me alegro de haberlo probado. Voy a tener que leer Ubik de Philip K. Dick...
Dystopicon está hecho en Unity, publicado para Windows. Pero funciona perfectamente con Proton 11 en Linux. Se publicó ayer en Steam al precio de USD 7.99/MXN 100.99 y está a un 15% de descuento durante las primeras dos semanas (hasta el 10 de agosto). Varios de los reviews en Steam son de usuarios que lo jugaron en Steam Deck, así que asumo funciona bien ahí también.

El post Reseña: Dystopicon - Steam fue publicado originalmente en Picando Código.
Picando Código
Programando y depurando tareas con Cron
julio 27, 2026 08:00 a. m.
cron es una de las tantas herramientas geniales de sistemas Unix. Nos permite programar tareas para que se ejecuten automáticamente en momentos determinados. Podemos programar comandos que se ejecuten a una hora determinada en el día, un día específico del mes, etcétera. cron tiene reputación por ser "complicado", pero no se lo merece. Como otras tantas aplicaciones, es cuestión de tomarse el tiempo de leer y aprender cómo usarlas.
Está disponible probablemente en todas las distribuciones Linux. Pero no siempre viene instalado por defecto. Algunas distribuciones usan systemd timers, que tengo entendido cumplen la misma función. Y seguramente haya alguna otra implementación nueva que no conozco.

Recientemente tuve que usar cron para programar la actualización de mi sitio web personal. El sitio usa Middleman para generar archivos estáticos dinámicamente. Solía tenerlo alojado en GitHub, generándose automáticamente mediante GitHub Actions. Pero al moverlo a un servidor de alojamiento web común, tenía pendiente la actualización automática. La experiencia me sirvió para aprender más sobre cron y comparto mi experiencia con la esperanza de que le pueda servir a alguien más también.
Dependiendo de cada sistema, los directorios y ubicación de distintos archivos puede llegar a variar. Esta entrada está basada en mi experiencia con Debian GNU/Linux 12 (bookworm) en mi Raspberry Pi. En mi caso, no tuve que instalar nada, ya que cron venía instalado por defecto. Sin caer en el comportamiento poco productivo de "RTFM", tengo que señalar que man cron es un recurso muy bueno para aprender a usar cron. No hay que tenerle miedo a las man pages, que man es por manual, no por hombre. Realmente ayudan a comprender mejor estas cosas.
cron se inicia automáticamente desde /etc/init.d al entrar en niveles de ejecución multi-usuario. Las tareas para cron se definen en archivos crontab (tablas cron). Hay tablas cron a nivel sistema, pero también tenemos archivos crontab específicos de nuestro usuario. cron se despierta cada minuto, examina todos sus archivos crontab y cada comando para ver si tiene que ejecutar algo en el minuto actual.
El archivo /etc/crontab es la tabla cron a nivel sistema. En este se especifican tareas y el usuario que debe ejecutarlas:
 fernando@raspberrypi
fernando@raspberrypi  ~ $ cat /etc/crontab
~ $ cat /etc/crontab# /etc/crontab: system-wide crontab
# Unlike any other crontab you don't have to run the `crontab'
# command to install the new version when you edit this file
# and files in /etc/cron.d. These files also have username fields,
# that none of the other crontabs do.
SHELL=/bin/sh
PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin
# Example of job definition:
# .---------------- minute (0 - 59)
# | .------------- hour (0 - 23)
# | | .---------- day of month (1 - 31)
# | | | .------- month (1 - 12) OR jan,feb,mar,apr ...
# | | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat
# | | | | |
# * * * * * user-name command to be executed
17 * * * * root cd / && run-parts --report /etc/cron.hourly
25 6 * * * root test -x /usr/sbin/anacron || { cd / && run-parts --report /etc/cron.daily; }
47 6 * * 7 root test -x /usr/sbin/anacron || { cd / && run-parts --report /etc/cron.weekly; }
52 6 1 * * root test -x /usr/sbin/anacron || { cd / && run-parts --report /etc/cron.monthly; }
Este archivo tiene algunas cosas específicas de Debian. cron tiene soporte y está predefinido para también ejecutar tareas en los crontabs hourly, daily, weekly y monthly, (cada hora, diario, semanal, mensual). Importante ver que las variables SHELL y PATH están definidas en el crontab, algo a lo que voy a volver más adelante.
cron también revisa el directorio /var/spool/cron/crontabs, que contiene los archivos crontab nombrados a partir de las cuentas de usuario en /etc/passwd. Por ejemplo:
fernando@raspberrypi ~ $ sudo ls /var/spool/cron/crontabs/fernando
Estos archivos se cargan en memoria, y no deberían ser accedidos directamente. Para acceder a ellos y actualizarlos debemos usar el comando crontab. El formato para definir una tarea cron es específico y está bastante bien documentado en los crontabs. Si ejecutamos crontab -l, podemos ver el archivo de tabla cron actual de nuestro usuario en el sistema. Para editarlo, ejeuctamos crontab -e.
Definiendo tareas para cron
La primera parte de una definición de tarea cron es la periodicidad. Son 5 campos que definen el minuto, hora, día, mes y día de la semana. Podemos usar asteriscos para definir "todos" y guiones para definir un rango. Por ejemplo el formato * * * * * dice "quiero ejecutar esta tarea cada minuto". El formato 0 6 * * * dice "quiero ejecutar esta tarea todos los días a las 6:00". Hay varias herramientas en línea para verificar la peroidicidad como crontab.guru y crontab.io.
Los guiones sirven por ejemplo para ejecutar una tarea sólo de lunes a viernes: 0 6 * * 1-5. O una tarea a ejecutar el primer día de cada mes a las 3 de la tarde: 0 15 1 * *.
La segunda parte de la definición de una tarea es el comando a ejecutar. Puede ser un comando directo o un script. Para cosas sencillas se puede ejecutar el comando directamente. Si por ejemplo ingreso esto en mi crontab:
Al minuto siguiente me voy a encontrar el archivo hola.txt en mi home con el texto "Hola mundo".
Ejemplo real: Depurando problemas con cron
Para el ejemplo real en el que quise usar cron, escribí un script para después llamar desde mi crontab. En la Raspberry Pi tengo un montón de cosas ejecutables en el directorio /home/fernando/bin/. Así que creé un directorio nuevo fb_site y ahí hice check out del código fuente del sitio. También ahí mismo cree el script publish.sh que ejecuta los pasos para generar el código nuevo y publicarlo (subirlo por FTP a un servidor):
cd /home/fernando/bin/fb_site && # Entro al directorio
source .env && # Cargo las variables de .env
cd /home/fernando/bin/fb_site/fb_site/ && # Entro al directorio con el código fuente del sitio
bundle exec middleman build && # middleman genera los archivos html, css y js
bundle exec middleman deploy # Publica los cambios por FTP
Como describo en el script: Entro al directorio necesario, cargo el archivo .env al shell para tener disponibles los datos para subir los archivos a FTP, voy al directorio del código y ejecuto los comandos middleman para generar el código en el directorio build y los publico por FTP.
El siguiente paso fue agregar el script a mi crontab personal con crontab -e. Quiero que el sitio se actualice todos los días a las 6 de la mañana, así que agregué al final del archivo:
Para probar, empecé cambiando la hora a "dentro de 1 minuto", para ver si el sitio se actualizaba.
Inicialmente el script no estaba funcionando. Así que empecé a pensar formas de depurar y encontrar la razón. Lo primero que podemos hacer es comprobar que el script se está ejecutando. Por ejemplo, agregando una línea que escribe a un archivo de log: echo "`date` Publicando fernandobriano.com" >> /home/fernando/publish.log. Volvemos a editar el crontab para que se ejecute en el próximo minuto, y comprobamos que se creó el archivo publish.log.
El script se estaba ejecutando correctamente, pero por alguna razón, las partes con Ruby no estaban funcionando. Fue ahí donde me sirvió lo que comentaba más arriba de redefinir PATH en el crontab. El momento "Eureka" (o "me cayó la ficha" más en uruguayo) fue cuando razoné que seguramente cron ejecutara un shell mucho más liviano que mi shell personal donde venía probando el script. Una prueba que podemos hacer en ese momento, es escribir a un log la salida del comando env, donde vemos todas las variables definidas para el usuario/shell en ejecución.
La ejecución de Ruby
Mi script necesita bundler para correr middleman, una gema Ruby. Estoy usando rbenv, como comenté por acá, para gestionar versiones de Ruby. Estas herramientas agregan valores al PATH para poder usar distintas versiones de Ruby en nuestro sistema. Una de las pruebas que me confirmó que iba por buen camino fue cuando imprimí el valor de which ruby en un archivo desde cron, y me mostró el Ruby instalado por el sistema (no Ruby 4.x, como venía usando con mi usuario).
Así que bajo mi usuario, ejecuté env y me fijé qué agregaba rbenv a PATH:
PATH=(...):/home/fernando/.rbenv/shims:(...)
Con esta información, modifiqué el script publish.sh para que también agregue este directorio al path:
fernando@raspberrypi ~/bin/fb_site $ cat publish.sh#!/bin/bash
echo "`date` Publicando fernandobriano.com" >> /home/fernando/publish.log
PATH=$PATH:/home/fernando/.rbenv/shims &&
cd /home/fernando/bin/fb_site &&
source .env &&
cd /home/fernando/bin/fb_site/fb_site/ &&
bundle exec middleman build &&
bundle exec middleman deploy
echo "`date` Publicación finalizada" >> /home/fernando/publish.log
Y listo, quedó funcionando y mi sitio fernandobriano.com se actualiza automáticamente todos los días. Espero que este post haya ayudado a perderle el miedo a cron y la experiencia de depuración le sirva a alguien más.
El post Programando y depurando tareas con Cron fue publicado originalmente en Picando Código.Picando Código
Por fín saqué mi sitio personal de GitHub
julio 24, 2026 09:37 a. m.
Finalmente saqué mi web personal, fernandobriano.com, de GitHub. Esta es la tercera o cuarta migración de servidor del sitio. Desde que Microslop compró GitHub, la plataforma ha ido empeorando cada vez más, como todo lo que toca Microslop. Cada día que uso GitHub veo más las consecuencias del slopware vibecodeado en lo que se ha ido transformando.
Empecé mi web personal (por lo que veo en la historia del repositorio git) en 2011 como una aplicación Rails (versión 3.1.0). Mi idea era tener un sitio "profesional" aparte de Picando Código, que pudiera compartir con potenciales empleadores. De paso lo usaba como experimento para aprender distintas tecnologías.
En 2011 estaba agarrando experiencia con Rails, así que me sirvió para tener un sitio más con Rails "en producción" e ir probando cosas. En su momento lo alojé en mi servidor, después en Heroku (que tenía alojamiento gratis para aplicaciones Ruby). Mirando los commits, mi aplicación se llamaba sharp-robot-1409 en Heroku.
 Más adelante migré el sitio a Sinatra, como prometí en este post sobre Sinatra. También le cambié bastante el diseño. Por ahí me puse a usar más mi tableta Wacom y empecé a agregar dibujos a mano en el diseño. Me gusta esa idea, creo que eventualmente lo voy a rediseñar con algunos dibujos más. Debería dibujar más, y agregar mis dibujos a los posts acá también...
Más adelante migré el sitio a Sinatra, como prometí en este post sobre Sinatra. También le cambié bastante el diseño. Por ahí me puse a usar más mi tableta Wacom y empecé a agregar dibujos a mano en el diseño. Me gusta esa idea, creo que eventualmente lo voy a rediseñar con algunos dibujos más. Debería dibujar más, y agregar mis dibujos a los posts acá también...
Desde 2014, el sitio funciona con Middleman. Middleman es un generador de sitios estáticos en Ruby. Tenemos todas las ventajas de poder usar código fuente en Ruby, pero el resultado final, y lo que ponemos a disposición en el servidor, es archivos estáticos HTML, CSS y JavaScript. Al tener el sitio alojado en GitHub, aprovechaba el uso de GitHub Pages para alojarlo. También usaba GitHub Actions para que el sitio se generara y actualizara automáticamente 3 veces por semana. Usé varias herramientas que facilitaban la publicación como middleman-gh-pages(última actualización en 2019) y middleman deploy (última actualización en 2017).
Ya al final en GitHub Actions tenía un script a mano que ejecutaba middleman build, el comando para generar los archivos estáticos, y usaba git a mano para copiar los archivos al branch gh-pages y hacer el push, sin herramientas intermediarias.
Al pasar mi sitio a un servidor personal, tuve que buscar cómo actualizarlo subiendo los archivos generados directamente por FTP (¡como en los viejos tiempos!). En principio, encontré un fork de middleman-deploy que funciona con FTP, pero también es bastante viejo. Podría mantener mi propio fork, pero lo que voy a terminar haciendo seguramente es escribiendo el código a mano para subir los archivos con net/ftp.
La parte "dinámica" del sitio obtiene estadísticas de descargas de plugins que he escrito para WordPress, gemas Ruby y obtiene el RSS de mi blog. También alguna cosa de GitHub que voy a terminar quitando porque ya no tiene tanta importancia como cuando GitHub importaba. Y esas estadísticas se muestran en el HTML estático. Algo interesante que encontré es que el código original para obtener información sobre los plugins de WordPress lo escribí en 2014. Y no es muy distinto al código que uso ahora.
El código ya no está más alojado en GitHub, sigo sacando cosas de ahí, intentando tener lo mínimo indispensable en ese sitio de Microslop. Voy migrando todo a Codeberg y mi instancia local de Forgejo.
Ahora que terminé esa migración pendiente, seguramente le dedique algo de tiempo a rediseñar el sitio, particularmente actualizar un poco el contenido. La otra tarea pendiente es tener un cron configurado para actualizar el sitio automáticamente a diario. Pero eso será material para otro post...
Picando Código
Entrevista a Àngel Beltran - Productor y Gameplay Programmer de Denshattack!
julio 21, 2026 08:00 a. m.
La semana pasada se publicó Denshattack!, un juego muy innovador y divertido, candidato a mejor juego del año. Con motivo de su publicación, después de jugar y reseñar Denshattack! entrevisté a Àngel Beltran de Undercoders. ¡Muchas gracias a Valeria y JF Games por el contacto!

Denshattack! es un juego espectacular, definido por muchos aspectos diferentes. ¿Cómo lo describirían a alguien que no ha visto ni un solo video o imagen?
La descripción corta que solemos utilizar es “Tony Hawk pero con trenes japoneses”, y la cara de sorpresa de quien lo escucha siempre es la misma (risas).
Denshattack! se entiende mucho mejor cuando lo ves en movimiento que al intentar describirlo con palabras. Es un juego que combina las principales pasiones de los miembros del estudio: skate, japón y trenes. Tomando estos tres conceptos como base, el juego incorpora elementos de videojuegos de deportes extremos, estética anime al más puro estilo shōnen y la increíblemente rica cultura japonesa, desde sus paisajes hasta sus bandas suburbanas e incluso su cultura culinaria.
¿Qué tal fue el proceso de desarrollo? ¿Cuánto tiempo tomó llegar al juego terminado?
Aunque han habido muchos retos a superar a lo largo del desarrollo, lo cierto es que ha sido el proyecto más divertido en el que hemos trabajado. Desde el primer prototipo desarrollado en abril de 2022 hasta el día del lanzamiento es un juego que no ha dejado de sorprendernos, incluso a nosotros.
Desde el inicio adoptamos la filosofía del “¿por qué no?”. Partiendo de un videojuego cuya premisa son trenes de cincuenta toneladas que hacen trucos de skate, cualquier idea parecía razonable, por alocada que fuera. Desde combates contra mechas gigantes hasta meter el tren en el ojo de un huracán o enfrentarse a un gigantesco gusano mecánico en el desierto.
No es que todas las ideas fueran buenas, sino que ninguna se descartaba de inicio por ser demasiado salvaje o arriesgada. Esto nos ha permitido incorporar constantemente nuevos elementos y conceptos que enriquecen la experiencia, siempre con el objetivo de sorprender al jugador en cada nivel.
La diversidad de mecánicas de juego incluidas es impresionante. Uno podría pensar que es un simple juego de hacer trucos, pero al jugarlo descubrimos muchos más. ¿Cómo se les ocurrieron tantas ideas juntas? Pensaría que no descartaron ni una. ¿Tuvieron que rechazar alguna mecánica? Imagino que habrá sido complicado lograr implementar tanta diversidad en un mismo motor dentro de Unreal.
¡Qué buena pregunta! Siempre tuvimos claro que no queríamos que Denshattack! fuera un “juego gimmick”, en el que la sorpresa inicial de ver un tren haciendo trucos de skate se perdiera rápido. Queríamos que eso solo fuera el principio, e ir sorprendiendo al jugador con cada nivel. Tomamos la filosofía de, partiendo de una estructura global, diseñar los niveles uno a uno, intentando superarnos con cada uno de ellos y proponer algo nuevo e impactante.
Esto supuso un gran reto, ya que poníamos toda la carne en el asador con cada nivel, y superarse implicaba sesiones de brainstorming para encontrar ideas todavía más alocadas y únicas. Por ejemplo, ya en el tercer nivel del juego caes sobre una noria, la conduces sobre el mar hasta chocar con una montaña que resulta ser un volcán activo y te ves obligado a escapar entre explosiones de lava. Un arranque así, con más de sesenta niveles en el juego, nos ha obligado a reinventarnos constantemente. Ha sido complicado pero también extremadamente divertido.
Siempre tuvimos claro que no queríamos que Denshattack! fuera un “juego gimmick”, en el que la sorpresa inicial de ver un tren haciendo trucos de skate se perdiera rápido.
La historia está bastante desarrollada y va muy conectada con el avance en el juego. ¿Cuál fue su enfoque e inspiraciones con la historia? ¿Cómo llevaron en paralelo la historia y el gameplay durante el desarrollo? ¿Empezaron desde el gameplay? ¿Hay mecánicas y niveles que se inspiraron en base al desarrollo de la historia y sus personajes?
Ha sido un proceso muy interesante. En todos los proyectos del estudio siempre priorizamos el gameplay por encima de todo, por lo que la base jugable es el núcleo sobre el que se construye todo lo demás.
En Denshattack! no ha sido distinto, los primeros prototipos se centraban exclusivamente en las mecánicas, pero los principales elementos de la narrativa estaban ahí desde el principio. Por un lado, la idea de embarcar al jugador en un viaje por Japón que lo llevara desde Beppu en el sur del país hasta Hokkaido en el norte; y por otro lado, los personajes, inspirados en las clásicas bandas suburbanas japonesas, como los Bosozoku o los Rockabillies, así como en anime tipo shōnen y juegos de lucha, en los que tienes personajes muy carismáticos con una visión única del mundo y un estilo propio.
Cuando entramos de lleno a la producción del proyecto, gameplay y narrativa se retroalimentaron e inspiraron mutuamente. A veces, el diseño narrativo de un personaje inspiraba un nivel, como en el caso de Madoka, la líder de las Bolamuerta. En su caso, se desarrolló su personaje definiéndolo como una violenta jugadora de baseball a la que expulsaron de su equipo por mal comportamiento, lo que la obligó a abandonar las ciudades cúpula y descubrir el salvaje mundo del Denshattack. Esto inspiró el combate contra ella en el juego, en el que te lanza pelotas de baseball que tienes que devolver haciendo trucos en el aire con tu tren, así como toda la estética de la banda, que combina elementos de baseball con los de la banda suburbana japonesa de las Sukeban.
Otras veces, una mecánica ha inspirado todo un arco narrativo, como en el caso de los Yukaze, unas corrientes de aire que se activan al realizar un truco y que permiten realizar una especie de doble-salto en el aire. En este caso, se diseñó primero la mecánica y esta inspiró toda la historia del “Viento fantasma” en el capítulo cinco.
Como digo, ha sido un proceso muy creativo en el que las líneas entre gameplay y narrativa se han difuminado mucho, generando un contexto que permitía que las ideas más interesantes y alocadas pudieran florecer.

Sé que es temprano, pero el mundo de Denshattack! tiene mucho potencial, tanto para próximos videojuegos como para otros medios. ¿Quedó algo pendiente? ¿Hubo algo que de repente no entró en el alcance del juego que les gustaría revisitar en el futuro? ¿Hay ideas como para más DLC, secuelas o explorar ese mundo en otros medios?
Hemos quedado muy satisfechos con Denshattack!, el juego final ha terminado siendo más grande y ambicioso de lo que inicialmente pensábamos, pero siempre quedan ideas en el tintero. Desde contenido adicional, que añada nuevos niveles y modos de juego, hasta incursiones en otros medios. Nos encantaría ver un manga de Denshattack en las tiendas, ¡o un anime! Uno puede soñar…
Por supuesto, todo esto dependerá del éxito del juego, pero creemos que el mundo de Denshattack tiene mucho potencial y nos encantaría explorarlo más en el futuro.
Nos encantaría ver un manga de Denshattack en las tiendas, ¡o un anime! Uno puede soñar…
¿Qué se sintió abrir el Nintendo Indie World Showcase este año? ¿Cómo se dio?
Fue increíble, uno de los momentos más emocionantes para el equipo. Desde que se anunció la Nintendo Switch 2 sabíamos que queríamos sacar el Denshattack! ahí, y fuimos afortunados de recibir los kits de desarrollo poco después de su lanzamiento. Cuando unos meses más tarde se dio la oportunidad de anunciar esta versión en un Indie World, casi no nos lo podíamos creer.
Trabajamos duro para crear el mejor tráiler posible, e incluso encargamos una escena animada específica, ¡lo que no sabíamos es que seríamos el primer juego anunciado! Estar todos juntos viendo el evento y que lo primero en salir fuera Denshattack! fue increíble para todos, uno de esos momentos que justifican todo el trabajo realizado durante años.
En la presentación hablan en catalán y el juego también tiene catalán como opción. Personalmente me encanta ver representación genuina de distintas lenguas en un contexto global con tremendo alcance. ¿Qué significa para ustedes tener la representación del lenguaje en el juego y darle una visibilidad tan grande?
La verdad es que es algo que nos salió natural. En la equipo hay gente de distintas partes del mundo, pero los que aparecimos en el evento hablamos catalán en nuestro día a día, por lo que cuando Nintendo sugirió que hablaremos en el idioma que nos resultara más natural, el catalán era la opción obvia, no había razón para hacerlo en ningún otro idioma.
Dicho esto, creemos firmemente en la importancia de las distintas lenguas y en que su representación en todos los contextos no hace sino enriquecer la conversación y acercar distintas culturas, ya que nuestro lenguaje y forma de hablar forma una parte vital de quienes somos. Tenemos el juego traducido al inglés, francés, catalán, alemán, portugués, japonés, chino y coreano, ¡pero si de nosotros dependiera estaría en muchos más!
... creemos firmemente en la importancia de las distintas lenguas y en que su representación en todos los contextos no hace sino enriquecer la conversación y acercar distintas culturas, ya que nuestro lenguaje y forma de hablar forma una parte vital de quienes somos

Siguiendo en esa línea, Cataluña es un centro importante de desarrollo de videojuegos a nivel global. ¿Por qué creen que hay una cultura tan grande y exitosa de desarrollo? ¿Cómo se iniciaron ustedes en los videojuegos y eventualmente en su desarrollo?
Hay varios factores para que se desarrollen tantos videojuegos en Cataluña. Por un lado, hay gran cantidad de universidades y escuelas que imparten cursos de desarrollo de videojuegos; esto atrae a editoras grandes, que ven la posibilidad de abrir estudios aquí con un coste de desarrollo considerablemente menor al de países como Estados Unidos o Inglaterra. Por otro lado, en España se ha generado una red muy interesante de estudios independientes que se retroalimentan a nivel creativo gracias a la existencia de eventos como IndieDevDay, Guadalindie o BIG.
Dicho esto, la industria catalana y española está muy lejos de ser ideal. Como ocurre en tantos otros sitios, la precariedad laboral está a la orden del día. Muchos estudios pasan grandes dificultades para encontrar financiación, y a menudo deben acudir a ferias internacionales como Gamescom, en Alemania, o Game Connection, en Francia, para reunirse con potenciales inversores de fuera. Hay un talento descomunal, pero también una enorme falta de inversión nacional e industria. Muchos proyectos sobreviven por la pasión de sus creadores, cuando no hay nada más imprescindible para crear como tener un contexto estable.
¿Se ha explorado la posibilidad de una versión física del juego?
¡Nos encantaría! En el pasado hemos logrado lanzar versiones físicas de muchos de nuestros juegos, pero casi siempre un tiempo después del lanzamiento en digital. Siendo un estudio pequeño, el éxito del lanzamiento digital es lo que nos abre las puertas a una posible versión física. Es una pena, porque nos encanta el formato físico y no hay nada como ver tu juego en la estantería, pero por el momento nos toca confiar en que haya buenas ventas de la versión digital.
¿Qué podemos esperar del estudio en el futuro? ¿Hay ideas de próximos juegos? ¿Alguna que nos puedan contar?
La verdad es que por primera vez en la historia del estudio no tenemos otro proyecto pensado al terminar el anterior. Denshattack! se ha vuelto tan grande y ambicioso que todos nuestros esfuerzos se han puesto en terminarlo y pulirlo lo máximo posible.
Dicho esto, ¡siempre hay ideas! Por un lado, nos encantaría ampliar el mundo de Denshattack! con actualizaciones y expansiones, tenemos muchas ideas de elementos que se han quedado en el tintero durante el desarrollo y que podrían ampliar todavía más el universo que hemos creado. Por otro lado, nos atrae la idea de crear nuevos juegos con conceptos tan sorprendentes como el de trenes haciendo trucos, aunque por el momento vamos a tratar de disfrutar del lanzamiento, ya habrá tiempo de pensar en qué vendrá después.
Finalmente, a pesar del estado actual de la industria del desarrollo de videojuegos, ¿qué consejo le darían a la gente que se está iniciando o se quiera iniciar en el desarrollo de videojuegos?
Qué pregunta más difícil… Como dices, la industria está en un momento muy complicado, las noticias sobre despidos y proyectos cancelados están a la orden del día. Nosotros nos sentimos muy afortunados de haber podido desarrollar y lanzar Denshattack! de la mano de una editora que confiaba en lo que estábamos haciendo, pero eso en estos tiempos no es lo habitual.
Me cuesta dar consejos porque hay un factor enorme de suerte que no se puede controlar, pero a alguien que empiece en esto le diría que trate de encontrar algo que haga sus proyectos únicos. En el contexto actual, donde la sobresaturación del mercado impide que juegos de muchísima calidad llamen la atención del público, nuestra manera de destacar ha sido crear algo tan diferente a lo demás que sea difícil de ignorar. Por supuesto, esto no garantiza el éxito, pero es una de las vías que yo exploraría si empezara de nuevo en la industria.
Por otro lado, le diría que no tenga prisa en hacer el juego de sus sueños. Denshattack! no ha sido nuestro primer proyecto, han habido varios juegos antes con una ambición más modesta que nos han hecho aprender muchísimo sobre cómo hacer juegos, qué se nos da bien y dónde podemos destacar. Denshattack! se cimenta sobre el aprendizaje de muchos juegos pequeñitos sin los cuales hubiera sido imposible afrontar un desarrollo de esta magnitud.
Por último, le diría que tratara de no perder la pasión por lo que hace. Esta industria es muy puñetera, y nada te garantiza que tendrás éxito, por lo que tienes que aspirar a disfrutar cada día de lo que haces. La meta no debería ser vender muchísimo, sino encontrar la manera de ganarte la vida haciendo videojuegos disfrutando de ello día a día.

Muchas gracias a Àngel por tomarse el tiempo de responder a mis preguntas con tanto detalle. Y felicitaciones a todo el equipo de Undercoders por el merecido éxito de Denshattack! Ha tenido una recepción excelente, siendo uno de los juegos mejores valorados por la crítica en lo que va del año. Es muy divertido y original, ¡lo recomiendo! Pueden leer mi reseña completa acá.
El post Entrevista a Àngel Beltran - Productor y Gameplay Programmer de Denshattack! fue publicado originalmente en Picando Código.Variable not found
Modo vacaciones on. ¡Nos vemos a la vuelta!
julio 20, 2026 06:00 a. m.

Variable not found
¡Microsoft MVPx16!
julio 16, 2026 06:05 a. m.

El 1 de julio de 2011 recibí por primera vez la notificación de que había sido reconocido como Microsoft MVP (Most Valuable Professional). Fue una sorpresa en toda regla, porque nunca pensé que mis aportaciones a la comunidad fueran lo suficientemente relevantes como para merecer este reconocimiento y, por supuesto, tampoco podía sospechar que alguien me hubiera nominado para ello.
No era consciente del impacto que ese nombramiento tendría en mi vida profesional y personal a partir de ese momento, pero sí del honor, con su correspondiente parte de vértigo y síndrome del impostor, que suponía formar parte de aquel grupo selecto de personas que compartían su experiencia y conocimientos con la comunidad de desarrolladores, y a las que admiraba desde hacía tiempo.
Desde entonces, cada mes de julio he seguido recibiendo puntualmente este nombramiento de manera consecutiva, y ayer me notificaron oficialmente el decimosexto reconocimiento como Microsoft MVP, por mi contribución a la comunidad de desarrolladores y mi implicación en la difusión de conocimientos sobre tecnologías Microsoft durante el año anterior. Todo un privilegio que me hace sentir muy orgulloso y, sobre todo, profundamente agradecido por haber sido considerado digno de pertenecer a este grupo durante tantos años.
Aprovecho este momento para agradecer a Cristina González Herrero y al resto de miembros del equipo del programa MVP que sigan apoyando mi trabajo y reconociendo mis contribuciones.
También quiero agradecer a todos los que me habéis acompañado en este viaje, ya sea leyendo mis posts, dejando comentarios, compartiendo mis contenidos o, simplemente, apoyando mi trabajo de alguna manera. Sin vosotros, nada de esto habría sido posible.
Y, por supuesto, a mi familia, por su paciencia infinita durante todos estos años. Su apoyo ha sido fundamental para poder llegar hasta aquí, así que este reconocimiento también lo celebraremos juntos, como la ocasión merece 😊
¡Seguimos!
Publicado en: www.variablenotfound.com.Picando Código
Reseña: Denshattack! - Nintendo Switch 2 y Steam
julio 15, 2026 03:00 p. m.
Denshattack! es un juego que combina manejar un tren con Tony Hawk's Pro Skater y aspectos de juegos de plataforma 3D. El estilo gráfico está inspirado por animé y juegos de la época del Sega Dreamcast. Puede sonar complejo, pero quédense conmigo que esto vale la pena. El juego es impresionante, es un título muy creativo que no esconde sus influencias, pero logra algo único, innovador y muy divertido.
Fue desarrollado por el estudio independiente de Barcelona Undercoders y publicado por Fireshine Games.

Viajo relativamente seguido desde Edimburgo a Glasgow, generalmente en tren. El viaje desde la estación de Haymarket hasta Queen Street en el centro de Glasgow es de aproximadamente unos 40 minutos. Cuando viajo solo tiendo a hacer el viaje parado. No me molesta y de paso dejar lugar a personas que de repente necesiten más que yo el asiento. Siempre voy con mis auriculares puestos, escuchando música.
Una pavada que hago mucho cuando estoy sólo en la sección cerca de las puertas (donde hay más espacio), es dejar de apoyarme o agarrarme y empiezo a mantener el equilibrio en el tren. Como si lo estuviera usando de skate gigante sobre las vías...
 Me pareció pertinente compartir esta anécdota ya que Denshattack! se puede describir como "Un juego de skate, pero con trenes japoneses". Asumimos el rol de Emi Araki, una repartidora de Ramen (en tren) viviendo en un Japón distópico en un futuro no muy lejano. Debido a la crisis climática la gente se empezó a mudar a cúpulas cerradas con aire purificado.
Me pareció pertinente compartir esta anécdota ya que Denshattack! se puede describir como "Un juego de skate, pero con trenes japoneses". Asumimos el rol de Emi Araki, una repartidora de Ramen (en tren) viviendo en un Japón distópico en un futuro no muy lejano. Debido a la crisis climática la gente se empezó a mudar a cúpulas cerradas con aire purificado.
Me gustó cómo la introducción empieza a contar esa historia medio sombría, y se interrumpe con un "¿a quién le importa eso?" y avisa que esto se centra en aquellas personas que se quedaron afuera.
En una de sus entregas, Emi conoce a Fernando (buena elección de nombre) Tamashiro. Él pertenece a una familia de diplomáticos de Perú, pero prefiere no contar mucho de ellos. Mi tocallo introduce a Emi al mundo de Denshattack, donde distintas tribus urbanas se enfrentan en batallas, carreras y retos con sus trenes.

Denshattack! (Steam) presentación de Fernando
Gracias a un par de escenas tutorial aprendemos a hacer los primeros trucos: ollies, flips y grinds, tanto en las vías como otros elementos del escenario. Esta es la mecánica central, pero en base a eso se construye una aventura inmensa, sumamente entretenida. Vamos a recorrer más de 60 niveles a lo largo de todo Japón, atravesando 8 regiones y 46 prefecturas.
Plataformas
Inicialmente empecé a jugarlo en Steam en Garuda Linux con Proton. Funciona a la perfección con Proton (versiones 10.0-4 y experimental) y está verificado para Steam Deck. Después me pasé a la versión para Nintendo Switch 2. En Switch 2 noté que funcionaba capaz que hasta mejor. Esto se debe seguramente a que la computadora que uso para jugar no es muy nueva ni de muy alta gama. Igual anda perfectamente en ambas plataformas.
Siempre prefiero jugar en la consola Nintendo por la ubicación de los botones A, B, X, Y. En Steam juego con el control de XBox 360, que si bien es cómodo, la ubicación inversa de los botones A B y X Y me hace tener que pensar o equivocarme al querer apretar los botones. Son demasiados años de usar los controles de Nintendo, perpetuando esa memoria muscular. Se pueden mapear los botones, pero es un tema menor. En Switch 2 lo jugué usando el Nintendo Switch Pro Controller (del Switch 1, no el de Switch 2).
Es ideal para jugarlo en pantalla grande en Nintendo Switch 2, pero también se ve genial en modo portátil.

Primeras impresiones
La primera vez que vi algo de Denshattack! fue durante el Indie World Showcase de Nintendo, en marzo. No sabía qué esperar, pero los gráficos se veían muy bien y el concepto interesante. También creí que de repente la mecánica de hacer trucos con un tren limitaría un poco el alcance, o se volvería monótono. Pero estaba muy equivocado. Es de destacar la cantidad de ideas que metieron en este juego. Si bien es un "Tony Hawk's Pro Skater plataformero", la diversidad de mecánicas es admirable. También me gustó que Ángel y David hicieron su presentación en Catalán.
Mi primera impresión al jugarlo fue ¡está buenísimo! Como mencioné antes, hay unas pantallas iniciales donde nos enseñan los movimientos básicos con el tren. Inicialmente aprendemos unas pocas maniobras, pero a medida que avanzamos en el juego se van acomplejando. Se van agregando botones y comandos al control que van a requerir un poco de habilidad y memoria. Pero esto se hace progresivamente, y siempre podemos volver a jugar un nivel para reafirmar una maniobra nueva.
Al agarrarle la mano, la jugabilidad se vuelve hasta rítmica y una vez que entramos en sintonía con el juego tiene ese flujo dinámico sumamente satisfactorio. Es similar a lo que sentimos en juegos de carreras o bueno... de Tony Hawk  . Si bien en regiones más avanzadas se vuelve un poco difícil, con la práctica y memorización obtenemos ese sentimiento de logro tan bienvenido.
. Si bien en regiones más avanzadas se vuelve un poco difícil, con la práctica y memorización obtenemos ese sentimiento de logro tan bienvenido.

Pura diversión
Además del aspecto tonyhawkero, es imponente la cantidad de mecánicas de juego que incluye. Sin quemar ningún detalle, puedo comentar cosas vistas ya en los tráilers como manejar un dron, pelear contra un kaiju gigante o hacer surf encima de un barco. ¡Pero hay mucho más! Incorporan un montón de cosas inesperadas que definitivamente no vi venir en un juego donde manejamos un tren. Hay mucha originalidad e ingenio, otorgando un factor sorpresa que nos mantiene enganchados.
Particularmente en las batallas con jefes, hay mucha creatividad para que la cosa se mantenga diversa, y que no sea "más de lo mismo". De repente me estoy repitiendo, pero me resultó súper innovador hasta dónde estiran la jugabilidad con las mecánicas base.
La historia se va relatando estilo cómic animado y con énfasis en distintos personajes. La ambientación es ese futuro post-apocalíptico, pero no cae en el estereotipo de que todo se vea todo oscuro y siniestro. Los escenarios son extremadamente coloridos, iluminados y muy variados dentro de la estética definida. La historia es interesante y nos da un contexto para ir avanzando de nivel en nivel. Pero podemos omitirla en todo momento si solamente nos interesa jugar con nuestro tren. Se puede interpretar un mensaje ecologista y anti-capitalista en el desenlace de la historia.
Como comenté, tenemos que recordar muchos comandos en el control: bocina, freno, salto, piruetas, y más. A medida que avanzamos, vamos agregando capacidades y complejidad a los controles, pero a un ritmo que se aprende con tiempo. El juego es relativamente fácil al principio, pero se pone bastante desafiante a partir del mundo 7. Necesitamos reflejos extremadamente afilados, y a veces es difícil ver qué obstáculos se vienen más adelante. Pero podemos repetir partes tantas veces como sea necesario, o volver a jugar una pantalla completa.

En algunas pistas se combinan un montón de obstáculos distintos que tenemos que enfrentar con habilidades y comandos del control. Hay mucho por recordar y a veces a este cerebro viejo no puede con tanto tan rápido. Apenas lo puedo procesar. Pero con la repetición y la práctica salen y sigue resultando satisfactorio cuando es así. Y esto es sólo en los últimos niveles del juego cuando ya tenemos todo aprendido y tiene sentido que nos desafíen para mantenernos entretenidos. Los obstáculos que más me trabajo me han dado son los que invierten la gravedad.
En cada nivel tenemos algunos objetivos opcionales, o logros, como "hacer tal pirueta sobre tal elemento", terminar sin chocar y más. También hay un ranking de puntaje y tiempo. Esto genera esas ganas de volver a jugar una escena al terminarla, porque "ahora que la conozco, la puedo hacer mejor". Si somos competitivos, o de querer completar al 100% un juego, vamos a volver a jugar cada escena una y otra vez hasta lograr la ejecución perfecta. No son niveles extremadamente largos, así que se presta para volver a jugarlos.
También tiene un elemento de exploración, un aspecto inspirado en juegos de plataformas 3D. Algunas escenas son un circuito cerrado con rutas alternativas donde necesitamos cumplir con ciertos objetivos. Otras son más directas, pero existen opciones de caminos alternativos y explorar. Algunos niveles son directamente carreras, donde competimos contra varios trenes intentando llegar primeros a la meta. ¡Son muy divertidas!

Denshattack! La pelea contra el kaiju Morzilla (que en español inevitablemente leeremos "morcilla")
Vamos a poder obtener distintos trenes así como personalizarlos con distintos patrones de color y stickers en el garage. El personaje de Fernando mantiene un fanzine sobre Denshattack y Japón en general. De a poco vamos obteniendo partes nuevas del fanzine con información de las bandas y las regiones. Es un agregado interesante, con algo de información real de la cultura y lugares de Japón. Por ejemplo que la prefectura de Ehime en la región de Shikoku es famosa por sus castillos, entre ellos dos de los 12 castillos originales de Japón.
Es un juego estilo Arcade, se puede meter unas partidas cortas durante unos minutos, o sumergirse por horas para avanzar la historia o volver a jugar pistas que nos gustaron. Terminar la historia principal lleva aproximadamente unas 10 horas. Pero hay mucho contenido extra y razones para volver a jugar las pistas, por lo que asegura unas cuantas horas más de diversión.
Entre las influencias más directas están los juegos de Tony Hawk's Pro Skater, Jet Set Radio, los juegos en 3D de Sonic y varios animé. ¡Hay hasta un Akira slide con trenes! Pero también se podría encontar un poco de influencia u homenaje a títulos de Nintendo como Splatoon y alguna cosa más en particular en el final.
La música
La música está muy buena y es muy variada. En algunas pantallas entré al menú de opciones y le subí el volúmen a la música por encima de todas las cosas. La banda sonora de Denshattack! está disponible en las plataformas de streaming así como en la página de Steam del juego. Tiene más de 80 pistas en total:

Conclusión
Denshattack! fue una muy grata sorpresa, un juego muy divertido con mucha innovación y creatividad y muchísimo valor de rejugabilidad. La mecánica central es muy entretenida y desafiante de dominar. Pero agrega también un montón de mecánicas que sorprenden y mantienen la frescura del juego. Espero se sorprendan y disfruten tanto como yo si deciden obtenerlo. Denshattack! está disponible para PC (Steam), Xbox Series X|S, PlayStation 5 y Nintendo Switch 2 a partir de hoy 15 de julio. Hay demos disponibles para descargar gratis en Nintendo Switch 2 y Steam por lo menos, por si les interesa probarlo y ver de qué se trata. ¡Lo recomiendo!

El post Reseña: Denshattack! - Nintendo Switch 2 y Steam fue publicado originalmente en Picando Código.
Variable not found
Enlaces interesantes 656
julio 13, 2026 06:01 a. m.

La versión 7.0 final de TypeScript ya está disponible. Si has ido probando las RC, ya habrás visto que el incremento de velocidad en compilación es espectacular. Y si no lo has hecho, estás tardando en actualizar.
David Grace nos muestra cómo es posible registrar los cambios automáticamente utilizando las tablas temporales en EF Core.
Al diseñar una API, cualquier comportamiento que expongamos puede ser utilizado por los clientes, y cambiarlo puede romper sus aplicaciones. Esto se conoce como la Ley de Hyrum, y Oren Eini cuenta cómo les afectó en RavenDB.
Waldek Mastykarz nos recuerda que, cuando hablamos de modelos IA, lo último no es necesariamente lo mejor. Si los adoptamos conforme aparecen, podríamos encontrarnos con sorpresas desagradables, como incrementos de coste, pérdidas de calidad o de predictibilidad. Lo más prudente es probarlos antes en nuestros escenarios concretos, y decidir a partir de ahí.
Los agentes de Microsoft Agent Framework para .NET ya pueden utilizar skills, por lo que podemos proporcionarles conocimientos especializados que cargarán bajo demanda cuando necesiten realizar tareas específicas. Nos lo cuenta Sergey Menshykh.
El resto de enlaces a contenidos interesantes, a continuación.
Por si te lo perdiste...
- La directiva @helper, ¿reencarnada en ASP.NET Core 3?
José M. Aguilar - Evitar el aviso de compilación "NETSDK1057: You are using a preview version of .NET" usando global.json
José M. Aguilar
.NET
- Fin del soporte de .NET 8 y .NET 9
CampusMVP - NuGet Versioning and Semantic Versioning (SemVer) in .NET & NuGet Package Metadata Best Practices: README, Icon, Tags, and License & How to Publish a NuGet Package to NuGet.org
Nick Cosentino - Improvements to reading Process outputs
Andrew Lock - Migrate Your WPF App to the Web, From Your Browser
Xaml.io - Agent Skills for .NET Is Now Released
Sergey Menshykh - You inherited a .NET codebase with zero tests. Now what?
Ebrahim Sayed Ebrahim
ASP.NET Core / ASP.NET / Blazor
- YARP and Aspire: "https+http scheme is not supported"
Bart Wullems - Using AI to Build a Blazor App 1: Start With the Problem
Jon Hilton
Conceptos / Patrones / Buenas prácticas
- Más allá del diagrama: Cómo defender la física de tu "System Design" en una entrevista Senior
Gerson Azabache Martínez - Worse is better: JSON versus XML
Mark Seemann - Why 90% Code Coverage Doesn't Mean Your Tests Are Good
Eli Lopian - The cost of a free feature
Oren Eini
Data
- EF Core Plugins: When Migrations Go Wrong & Owning Migrations with ExcludeFromMigrations
Martin Stühmer - EF Core and Azure SQL Database: A Step-by-Step Guide
Anton Martyniuk - Track every EF Core record change with temporal tables
David Grace - The N+1 Query Problem in EF Core: Detection, Diagnosis, and Permanent Fixes
Chris Woodruff
Machine learning / IA
- GPT-5.6: Frontier intelligence that scales with your ambition
OpenAI - Not all model upgrades are upgrades
Waldek Mastykarz - The hidden variables in your agent eval
Waldek Mastykarz
Web / HTML / CSS / Javascript
- Announcing TypeScript 7.0
Chanchal Kumar Vishwakarma - Get Ready For the Powerful CSS border-shape Property!
Temani Afif - How to Make an Interactive Element Invisible but Accessible
Daniel Schwarz - Boundary-Aware Styling in CSS
Preethi Sam - Thinking Horizontally in CSS @layer
Chris Coyier - Building a Scroll-Driven 3D Gallery Using a Blender Camera Path with Three.js and GSAP
Gaspard Hedde - Getting Started with Angular Signal Forms
Dhananjay Kumar
Visual Studio / Complementos / Herramientas
- Visual Studio June Update - Track Your Usage, Trust Your Tools
Mark Downie - Foundry Local Monitor — See every local AI model your machine is running with Foundry Local
Bruno Capuano - The .NET Host Process: What Runs Before Main() and Why It Sometimes Hangs
Dave McCarter - How Prompt Tuning Improved GPT-5.5 in VS Code
VS Code Team - Modernize .NET applications in the GitHub Copilot app
Michael Taylor
.NET MAUI / Cross-platform
- Available Now in .NET 11 for .NET MAUI
Leomaris Reyes
Publicado en Variable not found.
Variable not found
Enlaces interesantes 655
julio 06, 2026 06:00 a. m.

Aunque siempre estuvieron ahí, la moda de los agentes IA ha vuelto a llamar al escenario a los worktrees de Git, que permiten trabajar en varias ramas al mismo tiempo sobre el mismo repositorio. En este artículo, José Manuel Alarcón nos explica cómo funcionan y cómo pueden ayudarnos en nuestro día a día.
Cuando lanzamos peticiones desde .NET, lo habitual es esperar a que la respuesta llegue completa antes de procesarla, aunque a veces, si los datos a recibir son masivos, esto no escala bien. Pero, ¿y si pudiéramos procesar los datos a medida que nos van llegando? En este artículo, Nick Cosentino nos explica cómo hacerlo con HttpClient y Server-Sent Events.
Si sigues trabajando con .NET exactamente igual a como lo hacías hace unos años, quizás te vendría bien echar un vistazo al resumen que Simon Foster ha hecho de las novedades que se han ido incorporando a .NET desde la versión 5 hasta la 10, para ver qué cosas nuevas podemos aprovechar.
El resto de enlaces a contenidos interesantes, a continuación.
Por si te lo perdiste...
- Evaluación en cliente de EF Core
José M. Aguilar - Determinar el modo de renderización de un componente Blazor (versión 9 y posteriores)
José M. Aguilar
.NET
- .NET 8 and .NET 9 will reach End of Support on November 10, 2026
Rahul Bhandari - Packaging and Package Identity for .NET apps with WinApp CLI on Windows
Zachary Teutsch - Closed class hierarchies
Andrew Lock - Building an MCP Server in .NET Without Buying the Hype
Martin Stühmer - Claude Skills for .NET: Teach AI to Build Features Your Way
Anton Martyniuk - .NET 5 to 10: Key Features Introduced in Every Release
Simon Foster - Identity vs Principal: Modeling the Current User in .NET — AppointMe
BravoDev - HttpClient Streaming in C#: HttpCompletionOption, ReadAsStreamAsync, and Server-Sent Events
Nick Cosentino - Building a Windows Tray App by combining Microsoft.UI.Reactor and a Worker Project
Morten Nielsen - Writing a .NET Garbage Collector in C#
Kevin Gosse - How to match names in C# without exact string comparisons
Nick Harrison
ASP.NET Core / ASP.NET / Blazor
- Getting Inherited Controller Routes to work in ASP.NET Core
Rick Strahl - BlazorDX: Fastest Blazor Controls Ever
Michael Washington - Best Practices for Exceptions in ASP.NET Core
Assis Zang - ASP.NET Core Request Paths Reference
Sebastian Nilsson - .NET app returning a blank 500? Not with exception handlers
David Grace - Nullable GUID Route Constraints in ASP.NET Core
Sebastian Nilsson - Choosing the Right Telerik UI for Blazor Chart
Héctor Pérez
Data
- 5 EF Core Performance Anti-Patterns That Entity Framework Extensions Eliminates Chris Woodruff
- Add vs AddRange in EF Core: The Performance Myth You Need to Stop Repeating
Chris Woodruff
Machine learning / IA
- Previewing GPT-5.6 Sol: a next-generation model
OpenAI - What AI benchmarks are not telling you
Waldek Mastykarz - Introducing Claude Sonnet 5
Anthropic - Support Vector Regression with SGD Training Using C#
James McCaffrey
Web / HTML / CSS / Javascript
- The Shifting Line Between CSS States and JavaScript Events
Daniel Schwarz - Fluid Typography with progress()
Matthew Morete - Iterating faster with TypeScript 7
VS Code Team - Modern CSS Features That Replace Old Tricks
JsDev - What’s !important #14: Gap Decorations, random(), <select> field sizing, and More
Daniel Schwarz - TypeScript Just Became GitHub’s #1 Language: Here’s Why
Arunachalam Kandasamy Raja - Large JSON Files: Practical Processing Guide
JsTools
Visual Studio / Complementos / Herramientas
- Git worktrees en la era de los agentes de IA: la clave para trabajar en paralelo sin volverte loco
José Manuel Alarcón - Automating your Visual Studio extension builds with GitHub Actions
Ryan Luu - Master the Command Line with GitHub Copilot CLI:
Lee Stott - JetBrains Air lands on Windows
Valerii Tepliakov - WSL container is now available for public preview
Craig Loewen - Introducing the Safari MCP server for web developers
Saron Yitbarek
.NET MAUI / Cross-platform
- SkiaSharp 4.0 is here: announcing the first stable release
Matthew Leibowitz - Replicating a Travel App in .NET MAUI
Leomaris Reyes
Publicado en Variable not found.
Variable not found
Enlaces interesantes 654
junio 29, 2026 06:01 a. m.

En Blazor no existen "signals", como en Angular. Sin embargo, es posible crear algo similar, para conseguir que la UI se actualice automáticamente cuando cambian los datos. Steven Giesel nos explica cómo hacerlo.
Rick Strahl nos explica qué opciones tenemos para crear aplicaciones Windows que puedan ejecutarse tanto en modo consola como en modo GUI, y por qué ninguna de ellas es perfecta 👉
Los caracteres de salto de línea no son simplemente a CR y LF. En este post Gérald Barré nos explica qué debemos tener en cuenta para gestionarlos correctamente en .NET.
Y por último, ¿sabías que desde la llegada de .NET 10 hace unos meses puedes ejecutar un archivo C# directamente desde la línea de comandos? Puedes crear scripts, pequeñas utilidades y ejecutarlas de forma rápida sin necesidad de crear y compilar un proyecto completo. En este post te explico cómo hacerlo.
Enlaces a más contenidos interesantes, a continuación.
Por si te lo perdiste...
- Ejecutar directamente archivos C# desde línea de comandos con "dotnet run"
José M. Aguilar - Implementación de servicios gRPC con ASP.NET Core
José M. Aguilar
.NET
- File-based WinUI apps with Microsoft.UI.Reactor
Morten Nielsen - Avoiding ToString() allocations with StringBuilder.MoveChunks
Andrew Lock - TimeProvider Test Patterns That Hold Up in CI and Production
Martin Stühmer - Creating Dual Use Windows GUI and Console Applications
Rick Strahl - New lines are more than \r and \n
Gérald Barré - Can Claude Code build a .NET app with your code style?
David Grace
ASP.NET Core / ASP.NET / Blazor
- Making A Guided Animated Tour For A Blazor App
Michael Washington - Signals in Blazor
Steven Giesel - Generate a Kiota client at build time from an ASP.NET Core OpenAPI file
Gérald Barré - Blazor Basics: Implementing a Loading Indicator for Asynchronous Components
Claudio Bernasconi - Your first MCP server with ASP.NET
Tim Deschryver
Azure / Cloud
- A Better Way to View Logs in Kudu for Azure App Service on Linux
Tulika Chaudharie
Conceptos / Patrones / Buenas prácticas
- Structured Logging Patterns That Actually Survive Production
Martin Stühmer
Data
- Your Database’s Isolation Levels Don’t Mean What You Think
Durgesh Rajubhai Pawar - Scaling EF Core for Data Imports: From CSV Files to Millions of Database Rows
Chris Woodruff - EF Core: LINQ Querying: Filtering, Projections, and Performance & Relationships in C#: One-to-Many, Many-to-Many, and One-to-One & Performance Best Practices in .NET 10 & Testing with EF Core in C#: In-Memory vs SQLite for Unit Tests
& EF Core vs Dapper in .NET: When to Use Each
Nick Cosentino - BulkSynchronize in EF Core: Mirror Your Data in One Operation
Chris Woodruff
Machine learning / IA
- La IA no diseña mi sistema
Fernando Escolar - Ya no prompteas al agente, diseñas el sistema que lo promptea.
Alberto Díaz Martín - Models don't have preferences, they have context & When the model has never seen your code
Waldek Mastykarz
Web / HTML / CSS / Javascript
- Using Scroll-Driven Animations for Opposing Scroll Directions
Silvestar Bistrović - Alignment in CSS Grid Lanes
Patrick Brosset - prop-for-that: CSS reacts, JS just listens
Adam Argyle - Astro 7.0
Matthew Phillips & Emanuele Stoppa & Matt Kane - Better Auth: Framework-Agnostic Authentication Solution for TypeScript Apps
Manikanda Akash Munisamy - Let’s Play With Gap Decorations!
Temani Afif - The Field Guide to CSS Grid Lanes
WebKit Team - Introduction to Cloudflare Workers for Web Apps – Master.dev Blog
Adam Rackis
Visual Studio / Complementos / Herramientas
- npm v12: cómo preparar tus proyectos antes de que cambie su funcionamiento
CampusMVP - 10 Tools That Will Make Developers More Productive in 2026
Anton Martyniuk
.NET MAUI
- Replicating a Ticket Screen in .NET MAUI
Leomaris Reyes - Reduce XAML Boilerplate with .NET MAUI Global/Implicit Namespace + Source Generator
Anandh Ganesan
Otros
- Te pagan por tener criterio
Braulio Díez
Publicado en Variable not found.
Variable not found
Usar un servicio Scoped desde un Singleton en .NET
junio 23, 2026 06:05 a. m.

Seguro que alguna vez os habéis encontrado con la necesidad de usar un servicio registrado como scoped desde el código de un servicio registrado como singleton. Un caso típico es cuando en una aplicación ASP.NET Core tenemos un servicio corriendo en segundo plano (vaya, un BackgroundService) y necesitamos acceder a servicios que usan bases de datos o cualquier otro recurso que está normalmente asociado al ámbito de una petición HTTP.
Si intentamos inyectar directamente un servicio scoped dentro de un servicio singleton, obtendremos un error al iniciar la aplicación, durante el proceso de validación del árbol de dependencias, ya que el contenedor de .NET no permite esta combinación:
System.AggregateException: 'Some services are not able to be constructed
(Error while validating the service descriptor 'ServiceType:
Microsoft.Extensions.Hosting.IHostedService Lifetime: Singleton ImplementationType:
MyBackgroundService': Cannot consume scoped service 'MyDbContext' from
singleton 'Microsoft.Extensions.Hosting.IHostedService'.)'
Una posibilidad (peligrosa: ¡no hacer!) es deshabilitar esta validación inicial, pero esto solo ocultaría el problema y casi con toda seguridad nos llevaría más tarde a errores en tiempo de ejecución que podrían ser difíciles de diagnosticar y, en el peor de los casos, incluso tumbarnos la aplicación.
En este post vamos a ver la forma correcta de resolver el problema creando ámbitos personalizados dentro del servicio singleton, y usándolos para resolver los servicios scoped que necesitemos.
Entendiendo los ámbitos (scopes) en .NET
En .NET, la vida de un servicio registrado como scoped está asociada obligatoriamente a un ámbito (o scope), una abstracción que define el contexto de ejecución de una serie de operaciones durante un periodo de tiempo claramente delimitado.
Cuando desde cualquier punto de la aplicación se solicita un servicio de este tipo, el contenedor de dependencias creará una instancia y la asociará al ámbito actual. Luego, si vuelven a solicitarse instancias del mismo servicio dentro del mismo ámbito, se devolverá la misma instancia. Y finalmente, cuando el ámbito finalice, todas las instancias asociadas a él serán destruidas automáticamente, invocando al método Dispose() si el servicio implementa la interfaz IDisposable.
El concepto "ámbito" es flexible y depende del tipo de aplicación que estemos desarrollando.
Por ejemplo, en ASP.NET Core, un ámbito se crea automáticamente para cada petición HTTP. Esto permite que cada petición tenga su propia instancia de servicios scoped sin mezclarse con instancias creadas para satisfacer otras peticiones.
En Blazor, sin embargo, los ámbitos están muy ligados al modelo de hosting usado por los componentes. En Blazor Server Side Rendering, se creará un ámbito para cada petición; en Blazor Server, cada usuario conectado tendrá su propio ámbito, que permanecerá activo mientras dure la conexión; en Blazor WebAssembly, dado que no existen ámbitos separados para cada usuario o petición, por lo que todos los servicios scoped se comportan como singleton.
Pero la parte interesante es que podemos crear nuestros propios ámbitos o scopes en cualquier parte de la aplicación.
Creando ámbitos personalizados
Para crear un ámbito personalizado, necesitamos usar el servicio IServiceScopeFactory, que está registrado automáticamente en el contenedor de dependencias de .NET. Este servicio nos permite crear nuevos ámbitos bajo demanda, y luego usar estos ámbitos para resolver servicios scoped, con una vida limitada al ámbito que hemos creado.
Veamos un ejemplo práctico. Vamos a partir de un servicio scoped llamado MyDbContext que proporciona acceso a una base de datos, y un servicio singleton llamado MyBackgroundService que necesita guardar datos en la base de datos periódicamente.
var builder = WebApplication.CreateBuilder(args);
builder.Services.AddHostedService<MyBackgroundService>();
builder.Services.AddScoped<MyDbContext>();
var app = builder.Build();
app.MapGet("/", () => "Hello World!");
app.Run();
public class MyBackgroundService (MyDbContext dbContext) : BackgroundService
{
protected override async Task ExecuteAsync(CancellationToken stoppingToken)
{
while (!stoppingToken.IsCancellationRequested)
{
await dbContext.SaveToDatabaseAsync();
await Task.Delay(1000, stoppingToken);
}
}
}
public class MyDbContext: IDisposable
{
public Task SaveToDatabaseAsync()
{
Console.WriteLine("Saving to database...");
return Task.CompletedTask;
}
public void Dispose() { } // TODO release managed resources here
}
Si intentamos ejecutar este código, obtendremos el error mencionado anteriormente, ya que MyBackgroundService es un servicio singleton que intenta inyectar directamente un servicio scoped (MyDbContext).
Veamos cómo solucionarlo de forma correcta. En primer lugar, en lugar de hacer que el servicio singleton inyecte directamente el servicio scoped, haremos que inyecte el servicio IServiceScopeFactory:
public class MyBackgroundService (IServiceScopeFactory scopeFactory) : BackgroundService
{
...
}
A continuación, podemos utilizar el método CreateScope() de esta factoría para crear un scope cuando lo necesitemos. El objeto devuelto es un IServiceScope definida en el framework de la siguiente manera:
public interface IServiceScope : IDisposable
{
IServiceProvider ServiceProvider { get; }
}
El hecho de que implemente IDisposable ya nos da pistas de que el scope debe ser destruido cuando ya no lo necesitemos. Además, la propiedad ServiceProvider nos proporciona un contenedor de dependencias específico para ese ámbito, que podremos utilizar para obtener los servicios que necesitemos. En general, el patrón de uso es el siguiente:
using (var scope = scopeFactory.CreateScope())
{
// Solicitamos servicios _scoped_ dentro de este ámbito
// usando métodos como scope.ServiceProvider.GetService<T>() o GetRequiredService<T>()
}
Volviendo al ejemplo anterior, ahora podríamos decidir la duración del ámbito. Podríamos optar por:
- Crear un ámbito fuera del bucle
while, de modo que la misma instancia deMyDbContextse reutilice en cada iteración. - O bien, crear un ámbito nuevo en cada iteración del bucle, de modo que cada vez que necesitemos
MyDbContext, obtengamos una nueva instancia.
En nuestro caso, la segunda opción es la más adecuada, ya que nos aseguramos de que cada operación de guardado en la base de datos se realice con una instancia fresca de MyDbContext, evitando posibles problemas de concurrencia o estado compartido, además de minimizar el tiempo de vida de las conexiones a la base de datos.
Por tanto, el código final de MyBackgroundService quedaría así:
public class MyBackgroundService (IServiceScopeFactory scopeFactory) : BackgroundService
{
protected override async Task ExecuteAsync(CancellationToken stoppingToken)
{
while (!stoppingToken.IsCancellationRequested)
{
using(var scope = scopeFactory.CreateScope())
{
var dbContext = scope.ServiceProvider.GetRequiredService<MyDbContext>();
await dbContext.SaveToDatabaseAsync();
}
await Task.Delay(1000, stoppingToken);
}
}
}
¡Eso es todo! Ahora MyBackgroundService puede usar el servicio scoped MyDbContext sin problemas, creando y destruyendo ámbitos personalizados según sea necesario.
Publicado en Variable not found.
Arragonán
20 años
junio 23, 2026 12:00 a. m.
Cuando ya estaba por publicar el anterior artículo en el blog me di cuenta de que justo dos días antes el primer artículo de este blog había cumplido la friolera de 20 añazos el 14 de Junio. Menudo vértigo de golpe, así que intenté hacer un viaje en el tiempo haciendo memoria de por qué empecé a escribir.
¿Por qué empecé?
La época en la que tuve mis primeras experiencias laborales como desarrollador fue una en la que los blogs estaban en ebullición. Como buen junior, tenía mucha hambre por aprender, así que consumía información en webs de noticias de programación y en algunos foros. Pero poco a poco empecé a encontrar blogs de personas concretas y a empezar a usar lectores de RSS para seguirlos.
En mi segundo trabajo como programador terminé en Net2u_ (adquirida después por Everis y esta a su vez por NTT Data), entre otras cosas tuve la suerte de coincidir con Daniel Torres Burriel, cuyo blog, por entonces, era personal y en él escribía principalmente de usabilidad. Posiblemente habría tardado mucho más en plantearme escribir y publicar si no hubiera tenido algún referente cercano que ya lo hiciera.
Eso me ayudó a animarme a dedicar tiempo a escribir sobre lo que iba aprendiendo tanto en el trabajo como por mi cuenta. Para lo que compré este dominio, como tenía poca pasta contraté el hosting más barato que encontré, con PHP, pero sin base de datos, y monté un SimplePHPBlog que era la única opción que encontré en la época sin necesidad de una base de datos. Más adelante cambié a Wordpress hasta que hace unos años volví a simplificar usando Jekyll.
Y aunque había dicho en el anterior artículo que no quería andar retorciendo LLMs, la primera en la frente: estuve peloteando con Claude Code para analizar distintos puntos por los que ha pasado este blog en cuanto a frecuencia y temáticas, incluso terminó por hacer un perfil sobre mi recorrido profesional a partir de mis publicaciones.
Pero calma, me niego a hacer copy-paste de lo que me sacó.
La evolución
No recordaba el altísimo ritmo de publicación de los tres primeros años, con un pico de 89 publicaciones en 2007. Aquellas publicaciones solían ser bastante cortas, con curación de enlaces interesantes, snippets de código que me resultaban útiles, combinadas ocasionalmente con notas más personales. Mucho foco en PHP, Java y Javascript de la época.

A partir de 2008 coincidió que estábamos trabajando en Jobsket y que me puse por mi cuenta como freelance, sobre esa época bajó el ritmo y aumentó la longitud. Por entonces, el tipo de publicaciones era más trabajado y muy centrado en tecnologías, principalmente la apuesta en Groovy y Grails, algo de Rails y Javascript… Combinaba esto con apuntes sobre el emprendimiento en Jobsket o el freelancing.
Hacia 2010 empecé a combinar ese tipo de artículos con nuevas inquietudes, como empezar a ejercer cierto activismo alrededor de la apertura de datos por parte de las administraciones públicas como punto básico para una mayor transparencia, o a organizar y participar en comunidades locales como el colectivo Cachirulo Valley o Agile Aragón, o la serie #developars.
En 2013 empecé a publicar un resumen/retro semanal para obligarme a mantener una cadencia, al principio fui constante pero al cabo de un par de años fue decayendo. Por cuestiones varias fui perdiendo la motivación de hacerlo, y acumulaba varias semanas seguidas sin publicar hasta que decidí abandonarlo en 2016.
Hasta 2016 estuve publicando casi todos los meses principalmente gracias a esa retro semanal, pero a partir de 2017 reduje mucho mi ritmo de publicación aquí. Aunque ese año y el siguiente ya que estábamos emprendiendo con Coding Stones me curré algunos para el blog que teníamos en medium, ya más enfocados en metodología que en tecnologías concretas.
Entre 2019 y 2021 volví a tener un pico de frecuencia, manteniendo el enfoque más metodológico e intentando aportar cierta profundidad en los temas. Cosas como DDD, arquitectura de software, producto, testing, devops, equipos, etc. En buena parte, las restricciones por la pandemia hicieron que le volviera a dedicar más tiempo a escribir
Y a partir de 2022 hubo una caída en picado, pero combiné pequeñas píldoras muy técnicas con otros más trabajados y con foco más metodológico. Con un repunte en 2025, empezando por el artículo para Mosaic y compartiendo experiencias con un pequeño experimento .
How it started vs. How it’s going
Al escribir esto, me vino a la mente el meme How it started vs. How it’s going.
How it started: Escribir para aprender. How it’s going: Escribir para no olvidar lo aprendido.
Pero en el fondo, sigue siendo lo mismo: un sitio para intentar ordenar mis ideas.
Arragonán
Intentando recuperar rutina
junio 16, 2026 12:00 a. m.
Llevo unos meses en los que a ratos me entran ganas de publicar algo, pero luego me lío con otras cosas y lo voy dejando pasar, así llevo desde Octubre. En su momento quería escribir algo sobre mi incorporación a Mito como team contributor, pero como fui dejando pasar el tiempo fue perdiendo momentum para mi.
No pretendo escribir cosas hiper curradas, sólo intentar obligarme a ordenar ideas y plasmarlas por escrito intentando comunicarlas razonablemente bien. Y todo esto sin torturar ningún LLM, más allá de que me revise algún error gramatical o me dé feedback para ir mejorando mi redacción. Porque writing is thinking.

Voy a seguir publicando aquí frente a plataformas de terceros por eso de la web abierta y tal. Porque aunque en alguna ocasión del pasado me he currado mucho un artículo y eso a mi ego le gusta que tenga alcance, prefiero hacerlo bajo mi dominio aún a sabiendas de que va a tener infinitamente menos tráfico que los substacks, linkedins o mediums de turno
Como siempre en este blog mi intención es seguir publicando sobre temas relacionados con el mundillo del desarrollo de productos de software. Tengo algunos borradores empezados, algunos desde hace muchísimo y otros razonablemente recientes. De cualquier modo se aceptan sugerencias.
Header Files
Optimizando Mapas
mayo 09, 2026 03:00 p. m.
Introducción
Trabajar con contenedores clave y clave-valor es algo que hacemos en casi cualquier aplicación: cachés, registros de configuración, índices, asociaciones entre datos… La biblioteca estándar de C++ nos proporciona varias opciones, cada una con sus fortalezas y debilidades. La opción obvia es std::set (para clave) std::map (para clave-valor), pero hay casos donde sencillas optimizaciones en estos contenedores pueden reportar ganancias significativas en rendimiento.
En este artículo compararemos algunos contenedores estándar, y buscaremos los mejores casos de uso para cada uno, así como sugerencias simples que mejorarán el rendimiento significativamente. Simplificaremos el estudio centrándonos en los contenedores clave-varlos (std::map y similares), pero en general las sugerencias y comparaciones son las mismas para los contenedores de conjuntos.
std::map: lo obvio
Cuando necesitamos un contenedor clave-valor ordenado, std::map es la primera opción que nos viene a la mente. Su API es directa: insert (emplace), find, contains, erase, clear, operator[]… Lo que ocurre internamente es que mantiene un árbol binario de búsqueda (típicamente un árbol rojo-negro), lo que garantiza que las claves siempre estén ordenadas y que operaciones como inserción, búsqueda y eliminación tengan complejidad O(log n).
std::map<std::string, int32_t> items;
items["key1"] = 42;
auto it = items.find("key1");
if (it != items.end()) {
std::cout << it->second << '\n';
}
Hay pequeños cambios que son sencillos de aplicar y que pueden darnos mejoras en nuestro código. Por ejemplo, usar emplace en lugar de insert o de operator[] (en este segundo caso debemos tener cuidado ya que emplace no reemplaza el valor si la clave ya existe).
El orden de las claves es útil cuando necesitamos iterar sobre ellas de forma ordenada, y la complejidad logarítmica es aceptable para la mayoría de casos. Pero hay un problema que no es evidente a primera vista.
El problema de la caché
std::map organiza los datos en un árbol disperso por la memoria. Cuando iteramos o realizamos búsquedas, los saltos entre nodos generan fallos de caché frecuentes. Tras un fallo de caché, el procesador debe esperar (típicamente unos cientos de ciclos) para obtener la siguiente línea de caché desde memoria principal. En una búsqueda logarítmica sobre millones de elementos, estos fallos se acumulan.
Comparemos esto con un contenedor lineal en memoria: cada acceso tiende a cargar datos vecinos útiles. Es el fenómeno conocido como locality of reference.
El problema de los destructores
Imaginemos ahora otro escenario común: tenemos una función que crea un std::map, lo llena, lo usa y luego lo destruye. Si esta función se invoca frecuentemente (miles de veces por segundo), ¡el destructor se convierte en un punto caliente! El destructor debe:
- Liberar la memoria de cada nodo
- Llamar al destructor de cada clave
- Llamar al destructor de cada valor
Todo esto ocurre de forma dispersa en memoria. En aplicaciones con requisitos de latencia baja o rendimiento crítico, esto es problemático.
std::vector<std::pair<K, V>>: la opción contrarreformista
¿Y si simplemente usáramos un vector ordenado de pares? Podríamos insertar todos los elementos, luego ordenarlo una única vez (ver detalles al final del artículo) y a partir de ahí realizar las búsquedas usando std::lower_bound. Siempre que no necesitemos encontrar elementos mientras insertamos, esta estrategia tiene ventajas interesantes.
La complejidad de búsqueda sigue siendo O(log n), como en std::map, pero con el beneficio en la caché que proporciona un array contiguo. La latencia de fallos de caché es varios órdenes de magnitud menor. La inserción de elementos es prácticamente gratuita (es un emplace_back, o mejor aún si hemos podido reservar toda la memoria de antemano con reserve), y toda la memoria se libera de una sola vez.
Como contrapartida, si necesitamos búsquedas mientras insertamos, o si modificamos y reordenamos constantemente, los costes se disparan. Pero para el patrón de “llenar, buscar, destruir”, este enfoque es extraordinariamente eficiente.
Además, la destrucción de este contenedor es mucho más eficiente, ya que no hay que recorrer multitud de nodos dispersos en memoria, sino que se realiza una única liberación de memoria al final.
std::map vs std::vector ordenado
Resumiendo la comparación principal del artículo:
std::map<K, V>mantiene orden e inserciones/búsquedas dinámicas en O(log n), pero paga con peor localidad de memoria y más coste en destrucción.std::vector<std::pair<K, V>>ordenado también permite búsquedas en O(log n) tras ordenar, con mucha mejor localidad y destrucción más barata.- Si el patrón es “insertar todo -> ordenar -> consultar”,
vectorsuele ganar claramente. - Si necesitamos mantener el orden y consultar mientras vamos insertando,
std::mapsigue siendo la opción natural.
Potencia amplificada: vector<pair> con PMR
C++17 introdujo memory resources (PMR). La idea es simple: en lugar de permitir que cada vector asigne su propia memoria, podemos proporcionarle un resource que gestiona dónde y cómo se asigna dicha memoria.
std::pmr::unsynchronized_pool_resource pool;
std::pmr::memory_resource* resource = &pool;
{
std::pmr::vector<std::pmr::pair<std::string, int32_t>> items(resource);
// use the vector
}
El beneficio es significativo cuando el patrón es realmente frecuente. No sólo evitamos nuevas asignaciones (lo que libera presión en el allocator), sino que la latencia se regulariza porque la memoria ya está “caliente” en caché.
Nota: Si se usa C++14 o anterior, o el compilador no soporta PMR, siempre podemos recurrir a Boost.PMR, que contiene una implementación muy parecida.
Coletilla: std::unordered_map si no necesitas orden
Si el orden de las claves no es relevante, std::unordered_map es una opción normalmente mejor que std::map (aunque no siempre mejor que el vector ordenado). Usa una tabla hash internamente, lo que reduce la complejidad de búsqueda a O(1) en promedio (en el caso de usar cadenas de caracteres como clave, la complejidad suele ser O(m)).
std::unordered_map<std::string, int32_t> items;
items.emplace("key1", 42);
auto it = items.find("key1");
Aun así, el rendimiento real depende de la función hash y de la distribución de las claves. Cuando se usan cadenas de caracteres como clave, normalmente se habla de que la función hash es O(m), donde m es la longitud de la clave, es porque calcular el hash obliga a procesar todos los caracteres de la clave. Además, igual que std::map, no elimina por sí mismo el coste de destruir claves y valores si el contenedor se crea y destruye continuamente, aunque el overhead de destruir el contenedor como tal es menor ya que no está disperso en memoria.
Benchmarks
Sin entrar en grandes comparativas, a continuación mostramos una comparativa entre los tres contenedores mencionados en este artículo. En este experimento creamos N elementos aleatorios (la clave puede repetirse), buscamos N valores aleatorios, y luego destruimos el contenedor. Usamos 3 casos (de arriba a abajo): N = 10K, N = 100K, N = 1M.
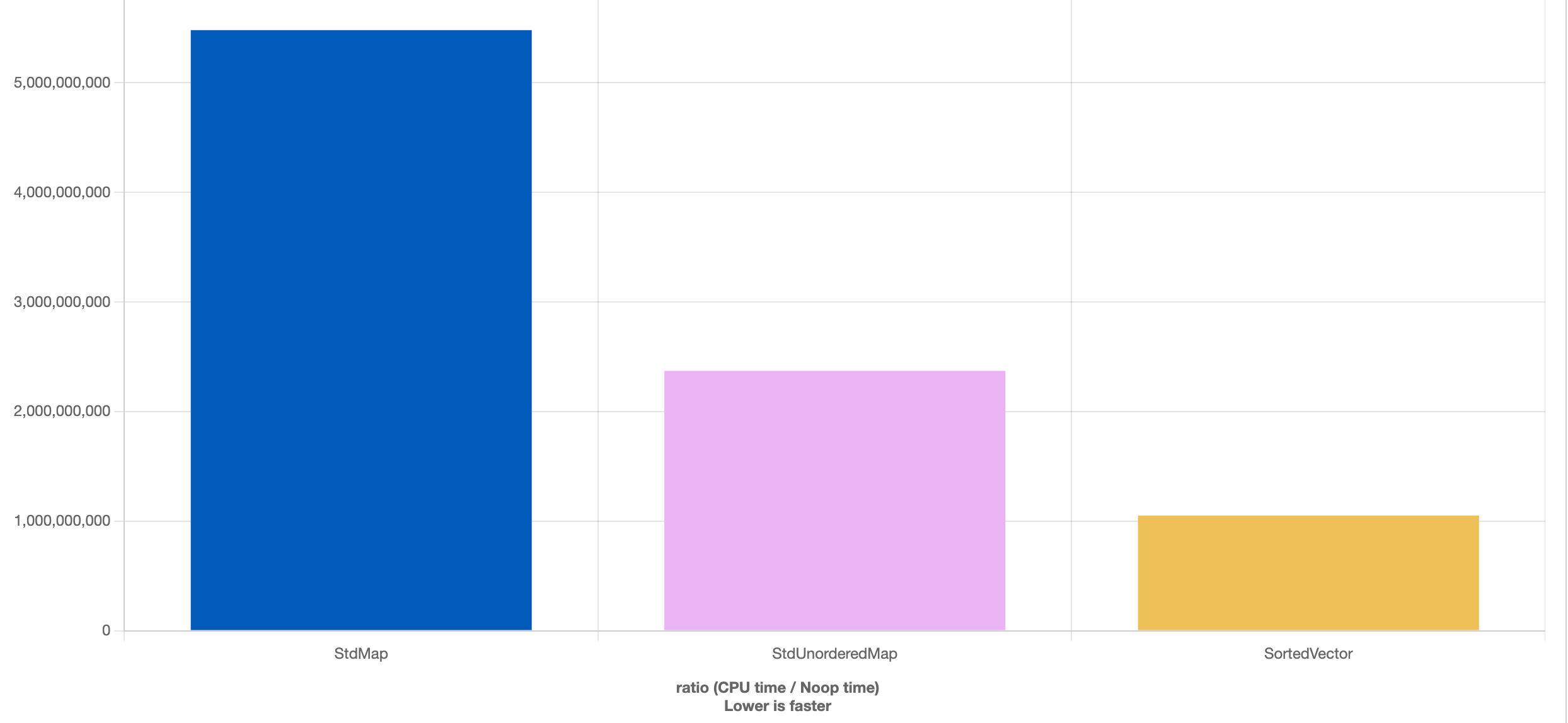
Podemos como el std::vector ordenado es más eficiente que los dos contenedores estándar cuando el número de elementos aumenta, lo que nos muestra la importancia de considerar la caché en nuestras optimizaciones.
Bonus: lo mismo aplica a std::set
Como mencionamos al principio, todo lo anterior es directamente aplicable a std::set y std::unordered_set. El razonamiento, las optimizaciones y los trade-offs son idénticos; simplemente sin el componente “valor”.
Conclusiones
La elección del contenedor clave-valor adecuado requiere entender más allá de la complejidad asintótica. Los detalles de memoria, caché y ciclo de vida del objeto son relevantes. En muchos casos, una solución “ingenua” resulta más eficiente que la opción obvia porque juega mejor con las características del hardware moderno.
La recomendación genérica sigue siendo: medir antes de optimizar. Pero si identificamos que un contenedor clave-valor es cuello de botella, empezaremos por considerar si afecta en realidad al caché, y si el contenedor tiene vida corta; si es así, vector<pair> ordenado probablemente sorprenderá.
Apéndice: ordenando std::vector
Al ordenar el std::vector debemos tener en cuenta la forma en que se comporte la inserción de elementos en un std::map: si se inserta un elemento con una clave ya existente, el valor se reemplaza. Para expresar esto en nuestro patrón insertar luego ordenar debemos primero mantener el orden de inserción durante el ordenamiento, y luego quedarnos con el último elemento del grupo que use la misma clave.
std::vector<std::pair<std::string, int32_t>> items;
// (Insert data here)
// Sort, keeping insertion order
std::stable_sort(items.begin(), items.end(), [](const auto& a, const auto& b) {
return a.first < b.first;
});
// Remove duplicates and keep last one
auto it = std::unique(items.rbegin(), items.rend(), [](const auto& a, const auto& b) {
return a.first == b.first;
});
items.erase(items.begin(), it.base());
// Binary searches
auto it = std::lower_bound(items.begin(), items.end(), "key1",
[](const auto& a, const auto& b) { return a.first < b.first; });
Navegapolis
… el siguiente paso: Spec-Driven Development para programar con IA
abril 25, 2026 12:36 p. m.
En el anterior post descubría los primeros pasos con Claude Code. Pero conocer la herramienta no termina de resolver el problema de fondo: al abordar una tarea grande con prompts, el código acaba funcionando, pero normalmente no como esperabas y sobre todo sin saber muy bien si la lógica final es la que tenías pensada.
Es lo que tiene el vibe coding. Vale para prototipos, pero se queda corto si el proyecto crece o lo toca más de una persona.
Parece que el siguiente paso es Spec-Driven Development (SDD): escribir primero una especificación clara — qué, por qué, reglas y criterios de aceptación — y dejar que esa spec sea la fuente tanto para nosotros, como para el agente de IA.
Este es un resumen de lo esencial: qué es, qué problemas resuelve, cómo encaja con TDD y BDD, las herramientas que van apareciendo y cuándo merece la pena el esfuerzo.
Como siembre, bienvenidas las sugerencias / críticas 
La entrada … el siguiente paso: Spec-Driven Development para programar con IA se publicó primero en Navegápolis.
Navegapolis
Claude Code: lo que me hubiera gustado saber desde el principio
abril 12, 2026 02:27 p. m.
Llevo unas semanas explorando Claude Code y como me ha pasado de todo, me he dado cuenta de que lo que más cuesta no es usarlo, sino organizar bien el trabajo.
Claude Code actúa como un agente de programación: lee el código, edita archivos y ejecuta comandos. Pero como en cada sesión arranca con la memoria en blanco, si el proyecto en el que estás no incluye la documentación que espera encontrar, en los archivos que espera encontrar y con los nombres que espera encontrar, es como tener un compañero brillante al que le tienes que presentar el proyecto cada mañana.
Empecé a base de intuición: una carpeta /docs por aquí, un archivo de esquema SQL por allá. Funcionaba, pero no del todo. Hasta que entendí cómo espera Claude Code encontrar la documentación del proyecto y cómo darle contexto entre sesiones.
He recopilado lo que he aprendido en estas dos guías que comparto por si os pueden ser útiles:
Primeros pasos con Claude Code — Para empezar desde cero: viendo que claude.ai no es lo mismo que Claude Platform (que no me resultó obvio al principio), cómo instalarlo, autenticar y hacer la primera sesión.
Buenas prácticas con Claude Code — Cómo estructurar las carpetas del proyecto, qué poner en el CLAUDE.md, cómo crear comandos personalizados y subagentes, y los errores que conviene evitar.
Las he escrito con la ayuda de Claude (sí, meta-recursivo), así que ha sido como hacer con él un curso acelerado para trabajar con él :-D.
Sigo aprendiendo, así que para los que vayáis por delante y veáis cosas mejorables o tengáis vuestras propias prácticas, se agradecen las sugerencias.
La entrada Claude Code: lo que me hubiera gustado saber desde el principio se publicó primero en Navegápolis.
Navegapolis
Scrum en la era de la IA: la síntesis que viene
marzo 15, 2026 04:37 p. m.
Nonaka y Takeuchi —que además de ser referentes en gestión del conocimiento, fueron quienes sembraron el concepto de Scrum en los años 80— describieron que el conocimiento evoluciona en espiral: una tesis funciona hasta que un cambio de contexto genera una antítesis, y de la tensión entre ambas nace una síntesis que integra lo mejor de las dos.
Scrum nació como síntesis de nuevo conocimiento al cuestionar el modelo de desarrollo en cascada de los años 80, mejorándolo con iteraciones cortas, equipos autónomos y entrega incremental.
Ahora el modelo de desarrollo vuelve a cambiar: la IA comprime ciclos, reconfigura equipos y cambia la forma de definir lo que queremos que construir. La espiral del conocimiento sigue girando: el marco inicial de scrum pasa a ser la tesis, la IA plantea la antítesis, y ya está tomando forma la nueva síntesis.
En este post intento de esbozar esta «síntesis»; no como una receta cerrada, sino dibujando el mapa de las zonas en las que la comunidad profesional ya está experimentando con evoluciones prácticas.
El sprint: más corto, más flexible, pero no prescindible
La cadencia de dos semanas ha sido el estándar de facto durante años, pero hay que recordar que no siempre fue así: las primeras iteraciones de scrum usaban ciclos de uno o dos meses. Fue la propia comunidad la que fue acortando la cadencia a medida que el contexto lo pedía. Con la IA, ese contexto ha cambiado otra vez: hay equipos que generan incrementos funcionales en días o incluso horas.
¿Significa esto que el sprint ya no sirve? No exactamente, el principio de trabajar en ciclos con puntos de inspección y adaptación sigue siendo esencial, lo que tenemos que cambiar es la duración y el formato.
Lo que está funcionando en equipos que ya trabajan con IA:
Micro-iteraciones dentro del sprint. El sprint se mantiene como contenedor de planificación y revisión estratégica, pero dentro de él el equipo ejecuta múltiples ciclos cortos de ideación-generación-validación con IA. El sprint se enriquece con un ritmo interno más rápido.
Sprints más cortos. Una semana o incluso menos, acercando la cadencia a la velocidad real de entrega.
Cadencia dual. Un ritmo rápido para exploración y prototipado (días) y otro más pausado para ingeniería de producción y validación (semanas). Esto conecta con un modelo emergente de «doble carril».
Se siguen manteniendo los momentos de reflexión. La retrospectiva es ahora más necesaria que nunca: los equipos están aprendiendo a trabajar con una tecnología nueva y necesitan espacios para evaluar qué funciona y qué no. Paradójicamente, es la velocidad de la IA la que hace más necesaria la pausa para pensar.
Equipos más pequeños, pero no sin estructura
La IA permite que equipos más reducidos logren lo que antes requería equipos grandes. La investigación de Harvard Business School (Dell’Acqua et al., 2025) afirma que equipos de 2-3 personas con asistencia de IA están consiguiendo resultados que antes requerían 7-10.
Cuando el equipo tiene como mucho 4 personas y la «voz» de una IA, algunas evoluciones que tienen sentido son:
- La daily puede transformarse en un check-in ligero, quizás asíncrono. En un equipo de dos o tres personas que se ven continuamente, una reunión formal de 15 minutos es desproporcionada.
- La planning puede simplificarse a una sesión de priorización y definición de especificaciones para la IA.
- La retrospectiva mantiene su valor pleno —quizás más que nunca— como espacio para evaluar cómo está funcionando la colaboración humanos+IA.
La idea no es eliminar eventos sino ajustar su peso al tamaño y la naturaleza del equipo. Algo que, por cierto, la agilidad siempre ha animado a hacer.
De las historias de usuario a las especificaciones (sin volver a la cascada)
Las historias de usuario son un medio de comunicación entre personas: «Como [usuario], quiero [acción] para [beneficio]». Son excelentes para transmitir intención. Pero cuando el interlocutor es una IA generativa, la intención no basta: la IA necesita contexto técnico, restricciones explícitas y criterios verificables.
Aquí entra una práctica que está ganando tracción: el Spec-Driven Development (SDD). La idea es que especificaciones detalladas se convierten en el artefacto del que la IA deriva código. Herramientas como GitHub Spec Kit ya formalizan este flujo: se describe qué se quiere construir, el agente genera una spec detallada, propone un plan, lo descompone en tareas y las ejecuta mientras el desarrollador revisa cambios focalizados.
La clave, y esto es importante, es no sustituir la historia por la spec sino relacionarlas en convivencia. La historia de usuario sigue es valiosa para capturar la intención y el contexto de negocio. La spec traduce esa intención a un lenguaje que la IA puede procesar. Y las specs deben ser documentos vivos que iteran como un backlog: se refinan, se adaptan, evolucionan.
Hay un riesgo aquí que vale la pena nombrar: si las especificaciones se vuelven rígidas y exhaustivas, podemos regresar al modelo de cascada sin darnos cuenta. La solución es tratar la spec como documentación operativa, no como un contrato inamovible. Es el lenguaje común entre humanos e IA, no burocracia.
Los roles: evolución.
Product Owner → Product Architect
Cuando la IA puede construir features más rápido de lo que la organización puede validar si son las correctas, el Product Owner se convierte en el factor limitante de la cadena de valor. Y eso, lejos de restarle importancia, se la multiplica.
Su evolución natural es hacia un Product Architect cuyo foco se desplaza de gestionar un backlog a ser el constructor de la decisión estratética: ¿qué se debe construir? Esto requiere competencias nuevas —data literacy, diseño de experimentos de validación, gestión de la tensión entre velocidad de producción y ritmo de validación—, la esencia del rol sigue siendo: maximizar el valor del producto.
Scrum Master → Agile Enabler
Quizá el rol donde más claridad se necesita. Lo que evoluciona no es la necesidad de alguien que facilite cómo trabaja el equipo, sino el alcance y la naturaleza de esa facilitación.
Cuando el equipo era un grupo de 7 personas, facilitar significaba sobre todo coordinar interacciones, eliminar impedimentos y proteger el espacio del equipo. Cuando el equipo es un sistema de 2-3 personas orquestando a agentes de IA, facilitar significa algo bastante más amplio:
Diseñar flujos de colaboración híbridos. ¿Cómo se divide el trabajo entre humanos e IA? ¿Estamos dando a la IA el contexto suficiente? ¿Revisamos sus outputs con el rigor adecuado? Alguien tiene que facilitar estas preguntas y optimizar estos flujos.
Gobernanza ética y de calidad. ¿Quién rinde cuentas cuando un agente comete un error? ¿Cómo gestionamos los sesgos? ¿Qué políticas de uso necesitamos? El facilitador ayuda al equipo a desarrollar estas políticas como práctica viva, no como imposición burocrática.
Gestión de la confianza. Los datos muestran desconfianza de los desarrolladores en el código o trabajo generado por IA. El facilitador ayuda a construir una relación sana con la IA: ni confianza ciega ni desconfianza paralizante. Esto requiere las mismas competencias de inteligencia emocional que siempre definieron al buen Scrum Master, aplicadas a un contexto nuevo.
Coaching del cambio. La transición hacia equipos potenciados con IA no es solo técnica: es cultural. Hay resistencias, curvas de aprendizaje desiguales y dinámicas que cambian cuando la IA redistribuye capacidades. Facilitar esa transición es trabajo de un profesional experimentado en dinámicas humanas.
Pensamiento sistémico. El facilitador evolucionado no ve eventos aislados sino el sistema completo: cómo fluye el trabajo, dónde se generan cuellos de botella, cómo interactúan los loops de feedback y qué consecuencias no intencionadas produce el uso de IA.
En resumen: el Scrum Master se transforma en alguien que facilita sistemas de trabajo más complejos, donde la complejidad no viene solo de las personas sino de la interacción entre personas e inteligencias artificiales.
Developers → Product Builders
El equipo de desarrollo evoluciona hacia perfiles que combinan herramientas no-code, generación de código asistida por IA y comprensión profunda del producto. Su valor se desplaza desde la implementación hacia la orquestación: diseñar arquitecturas, escribir especificaciones, revisar lo que la IA genera y asegurar estándares de calidad.

Calidad: el frente donde más atención hace falta
Este es posiblemente el punto más delicado de toda la evolución. Los datos invitan a la prudencia: sin controles deliberados, la IA acelera la acumulación de deuda técnica. El equipo va más rápido, pero el código puede volverse frágil y costoso de mantener.
Las prácticas que están emergiendo como respuesta son sensatas y pragmáticas:
- IA supervisando IA: una IA como revisora automática de lo que otra genera, con semáforos y revisiones automatizadas.
- Specification by Example: tests con especificaciones concretas y verificables. La IA no puede corregir sus propios deberes.
- Definition of Done reforzada: adaptada para código generado por IA, incluyendo revisiones de seguridad, análisis estático y verificación de no-duplicación.
- Auditoría continua de deuda técnica: monitorización activa de métricas de salud del código como contrapeso a la velocidad.
Aquí es donde los principios de inspección y adaptación se vuelven, si cabe, más necesarios. La velocidad sin validación es desperdicio.
Dos incorporaciones emergentes que vale la pena conocer
El Doble Carril (Double-Track)
Un carril rápido (Vibe Coding) para crear prototipos no liberables a producción, validar ideas rápidamente usando IA y no-code. Aquí la calidad del código es secundaria; lo que importa es la velocidad de aprendizaje.
Un carril robusto (Vibe Engineering) que asegura estándares de ingeniería, seguridad y calidad para lo que va a producción. Aquí se aplican SDD, Definition of Done reforzada y QA.
La separación entre carriles no es nueva —el dual-track agile existe desde hace años—, pero la IA la hace más explícita y necesaria. La velocidad del carril rápido puede ser 10x-100x mayor que la del robusto, lo que exige gestión consciente de cuándo una idea pasa de uno a otro.
IA como Teammate
El framework de Scrum.org propone cuatro pasos para integrar la IA como compañero de equipo: selección de modelos, provisión de contexto, prompt engineering y gobernanza. Es un enfoque más conservador, directamente compatible con Scrum actual y adoptable de forma incremental. Un buen punto de partida para equipos que están empezando.
La espiral sigue girando
Scrum es conocimiento abierto. No es un modelo «propietario» que tenga una definición en exclusividad. Emergió desde abajo, construido por la comunidad profesional, y así ha evolucionado siempre: los sprints se acortaron, las retrospectivas se generalizaron, el refinamiento del backlog se formalizó.
La integración de la IA es el siguiente capítulo natural de esa evolución. Los equipos ya están experimentando con nuevas formas de trabajar. Algunas se están articulando como prácticas emergentes. La síntesis está en construcción.
No hay que esperar a que nadie nos dé permiso. Es lo que siempre hemos hecho.
La entrada Scrum en la era de la IA: la síntesis que viene se publicó primero en Navegápolis.
Picando Código
Reseña: Vultures - Scavengers of Death - Steam
marzo 11, 2026 09:00 a. m.

Vultures - Scavengers of Death es un juego de survival horror por turnos, con inspiración en clásicos como Resident Evil y Parasite Eve. Los gráficos están estilizados como recuerdo el primer Resident Evil en PlayStation. Se ven bastante poligonales, pero optimizados para pantallas modernas con alta definición. Manteniendo una personalidad retro, con las ventajas que traen muchos años de experiencia y avances tecnológicos en videojuegos.
Me gusta que se aprecie el estilo creado a partir de las limitaciones de hardware de tiempos anteriores. Sobretodo cuando hoy hay mucho menos limitaciones tecnológicas. En materia creativa a veces los límites fomentan la creatividad, y se generan expresiones gráficas clásicas que no pierden vigencia, como ésta. Por cierto, Resident Evil cumple 30 años el próximo Domingo 22 de marzo.
Mi experiencia con Resident Evil es muy reducida. Recuerdo haberlo jugado una vez que fui a la casa del amigo de un amigo donde había un PlayStation 1 conectado a un televisor CRT de 14 o 21 pulgadas. Éramos varios charlando mientras nos íbamos turnando para jugar un poco. Qué buenos tiempos aquellos de adolescente donde andaba callejeando por Maldonado y terminábamos jugando PlayStation en un apartamento y esa memoria vendría a mi cabeza décadas más tarde para reseñar un juego.
En Vultures - Scavengers of Death, la ciudad colapsó tras una explosión en un centro industrial que transformó a la población en zombis. En una metrópolis sellada bajo cuarentena total, asumimos el rol de un agente de la unidad de mercenarios VULTURES. Fuimos contratados para alcanzar la cima de la torre Nakat... Eugenesys y con suerte encontrar una cura.
El juego tiene esa característica opresiva del horror de supervivencia que tenemos que gestionar bien los recursos. La munición es limitada y no tenemos un amplio arsenal de armas para entrar cuarto por cuarto eliminando zombies a diestra y siniestra. También necesitamos recurrir a la estrategia, porque tirarnos de frente contra todo enemigo que nos encontremos no nos va a ayudar a progresar. Los desarrolladores comentaron que tuvieron en cuenta éstos factores, fundamentales en los géneros que combina, a la hora de diseñar armas y equipamiento.
El cazador ciego, una de las "criaturas" de Vultures - Scavengers of Death
Un aspecto particular que puede sonar raro si conocemos los títulos en los que está inspirado, es el combate por turnos. No sé si ya se había hecho un juego así con aspectos de horror de supervivencia. Pero me resultó diferente e interesante. Los desarrolladores hablan bastante del tema en la página de Steam. Ese post en particular nos aporta un montón de información sobre las características del juego y cómo llegaron a ellas.
Su idea es permitirnos tiempo para pensar qué hacer en cada situación, pero también ofrecer algo poco convencional dentro del género. A lo que tenemos acciones limitadas y tiempo, podemos evaluar las opciones y armar una estrategia. Citan a Breach, Colony Ship, Xcom, y Dungeon and Dragons como inspiración para el combate. Todo surgió de hacer un roguelike a lo Resident Evil en una terminal retro de los 80, usando comandos de texto. Así destilaron las mecánicas clave de survival horror y las tradujeron al contexto de un juego de tablero.
Agregan también que consideraron tener niveles generados procedimentalmente. Pero llegaron a la conclusión que no era la mejor opción. Su explicación me parece muy buena, pueden leerla en el enlace anterior.
Estoy de acuerdo que si bien generar los escenarios es técnicamente viable (y en algunos casos agrega mucha variedad), para cierto tipo de juegos es difícil lograr el balance y sensaciones adecuado. Personalmente prefiero algo más "curado", como esto, donde los desarrolladores tienen que definir cada nivel, jugarlo y ver cómo se siente. De repente queda esa opción para más adelante.
El juego está hecho con Godot, el motor de desarrollo de videojuegos multiplataforma software libre. Me encanta ver juegos de calidad hechos con Godot. Está muy bueno ver la variedad de estilos y mecánicas que se pueden lograr con esta herramienta. Ya he comentado que estuve experimentando y desarrollando un poco con Godot, y me gustó bastante lo que pude lograr con relativamente poco estudio y experimentación. Voy a ver si en algún momento vuelvo.
¡Es un juego Colombiano! Está desarrollado por Vultures Team: Mateo y Giovanni son amigos y compañeros con más de nueve años de trayectoria creando juegos y software juntos. Destacan por desarrollar mecánicas experimentales y adoptar un estilo artístico retro y poco convencional. En ocasiones, sus juegos incorporan toques de crítica social y política, cuestionando a menudo la sociedad de consumo y el capitalismo desenfrenado.
He estado jugando la demo en Steam, disponible en varios idiomas incluido el Español. Podemos jugar con Leopoldo, uno de los (al menos dos) personajes disponibles e incluye completa la primera misión.
Nos encontramos en una jefatura de policía, donde irán apareciendo los primeros zombis. La mayoría son oficiales de policía, y los podemos atacar con una pistola, un cuchillo y cócteles molotov. Más adelante podemos obtener una escopeta, que ataca más de un espacio a la vez y empuja a los enemigos. Ideal cuando tenemos un grupo de zombis enfrente.
¡Fuego! ¡Fuego al zombi policía! Mujajajajaja... El molotov es más efectivo para atacar más de un zombi, pero necesitaba probarlo.
A medida que vamos jugando, vamos desbloqueando cosas y se va poniendo más interesante. Las primeras pocas veces que jugué el demo, no lograba engancharme. Moría relativamente rápido y no avanzaba mucho. Pero con unas pocas jugadas más le fui agarrando la mano y disfrutándolo más. Son importantes las palabras de sus desarrolladores sobre la estrategia. Es mejor tomarse un tiempo y ver qué opciones tenemos, que ir adelante y atacar. Cuando lo enfrentaba como un juego de acción, generalmente terminaba viendo la pantalla de partida perdida. Por suerte cuando perdemos, si decidimos continuar, empezamos en la última puerta que atravesamos.
Para ayudar nuestro progreso, vamos a ir encontrando cosas útiles en el camino. Los botiquines de primeros auxilios los podemos usar para curar al personaje, hay computadoras para guardar el progreso y dispensadores de agua que también recuperan un poco de salud.
Nos podemos mover libremente por la grilla de cada cuarto, pero si un zombi nos detecta, entramos en modo combate. En el modo combate tenemos puntos de acción y movimiento limitados para realizar acciones de ataque, movernos, cambiar de lugar con un enemigo, empujar, curarnos y más.
A la hora de explorar, podemos elegir entre tres modos para desplazarnos: caminar, correr y sigilio. A medida que avanzamos aprendemos lo importante de ir usando cada uno. Cuando volvemos por cuartos que sabemos son seguros, o recorremos pasillos, vamos a querer ir corriendo. Luego en general caminando, pero el sigilio va a ser un arma casi que imprescindible. No sólo nos permite evitar la detección por los zombis, también podemos hacer ataques estratégicos. Es importante tener en cuenta la posición y las ventajas que podemos conseguir para evitar que nos dañen. O directamente podemos evitar totalmente el combate, para ahorrar balas y energía.

En esta habitación perdí por enfrentarme a todos los zombies a la vez. Con sigilio me pude ir acercando de a poco a cada uno y apuñalarlos antes que me vieran, dándome un ataque de ventaja. También, las mesas están en posiciones que nos permiten ocultarnos o definir por dónde se van a mover los zombies si nos atacan.
La historia se va a ir descubriendo interactivamente por medio de documentos y otros ítems que revelan qué pasó. Asimismo recolectamos llaves o pistas para abrir distintas puertas que en principio se encuentran bloqueadas. Me resultó imprescindible usar el mouse y teclado a la vez. Se podría jugar sólo con el mouse, pero resulta mucho más práctico ir aprendiéndose los atajos de teclado para cambiar el modo de caminata, el arma, etc. ágilmente.
La demo lleva entre 40 y 50 minutos de juego promedio. Termina cuando llegamos al final del primer nivel en la jefatura. Hicieron un buen trabajo con esto último, la historia se va desenvolviendo y se pone interesante a medida que avanzamos. Para cerrar, vemos que al igual que en Resident Evil, no van a ser sólo zombies los monstruos sueltos. Recomiendo probar la demo, sobretodo si te gusta cualquiera de los títulos nombrados como inspiración. Y ya se puede agregar a la Wishlist de Steam si te interesa.
El juego completo está planeado publicarse en Abril de 2026. Incluirá más niveles y a Amber, una mercenaria aparentemente inspirada en Motoko Kusanagi. Se destaca por sus movimientos rápidos y sigilosos, y cuenta con un gameplay distintivo. Está disponible en Steam para Windows, pero me funcionó perfectamente en Garuda Linux con Proton 10.0.4. Está hecho en Godot, así que salvo que tenga algún componente exclusivo para Windows, de repente el juego completo tiene una versión nativa para Linux.

El post Reseña: Vultures - Scavengers of Death - Steam fue publicado originalmente en Picando Código.
Navegapolis
Legado digital
marzo 05, 2026 12:09 p. m.
Explorando cómo programar con IA, el episodio “La muerte digital” del podcast DECODE de Dani Sánchez-Crespo (DaniNovarama) me dio la idea de hacer un programa para el reto que plantea: ¿qué pasa con tus contraseñas, seguros, accesos bancarios y documentos privados si un día no estás? ¿Cómo puede acceder tu familia?
Así que aprovechando la fiesta del 5 de marzo (para eso hay que ser de Zaragoza )este es el resultado: Legado Digital: un único ejecutable que se puede guardar en un pendrive, sin instalación. Almacena la información cifrada con AES-256-GCM y Argon2id.
Esta es la información de lo que he usado, y la aplicación, por si os puede ser útil:
He usado:
- Antigravity coon Gemini3.1 Pro.
- Go para el motor de seguridad.
- base de datos SQLite (en memoria)
- Svelte + TailwindCSS para la interfaz
- Wails v2 para empaquetarlo todo en un único binario de Windows.
El programa lo podéis descargar en el enlace de abajo que tiene el ejecutable y un txt de instrucciones, que comparto tal cual, sin compromisos de licencia ni mantenimiento para los que os pueda resulta útil.
La entrada Legado digital se publicó primero en Navegápolis.
Meta-Info
¿Que es?
Planeta Código es un agregador de weblogs sobre programación y desarrollo en castellano. Si eres lector te permite seguirlos de modo cómodo en esta misma página o mediante el fichero de subscripción.
Puedes utilizar las siguientes imagenes para enlazar PlanetaCodigo:
![]()
![]()
Si tienes un weblog de programación y quieres ser añadido aquí, envíame un email solicitándolo.
Idea: Juanjo Navarro
Diseño: Albin